I am using the communication hook to implement a simple top-k gradient compression that uses all_gather to gather the indices and values. However, I found that after some iterations, all_gather will hang and throw no errors.
To debug, I removed complicated operations, and only left the async all_gather call as below:
the hanging problem still happens.
I am registering this model to a resnet32 (DDP for sure) on cifar-10. I saw other people with similar problems were not making the output list on different devices, but I believe I’ve set them correctly in my case as in the code snippet.
The pytorch version was 1.9. But I also tried on Pytorch 1.12 (changed some code as the APIs changed), same problem.
Also, as I was thinking if it is the problem of the all_gather primitive, I changed the first all_reduce to an all_gather then take the average, and remove the second all_gather. But it turned out won’t get stuck. So the problem will lie in my code. But I am really confused about what could be the possible reasons that make this code stuck.
Glad you found a workaround.
To your original question – can you check if all_indices have the same size on all ranks? If not, this could easily lead to a hang in all_gather.
Yes thank you! In my previous search, I didn’t know different sizes would lead to a hang too, and I just verified with my original code, yes there was a size mismatch because sometimes top-k is not exactly k values.
By the way, I still have two (unrelated) questions:
the GradBucket’s API is changing among versions, in 1.9 there’s a get_tensor_per_parameter, but in 1.12 it’s gone and replaced by parameters() and gradients(), I wonder what is the difference between them? Because as far as I know, all tensors in GradBucket are gradients.
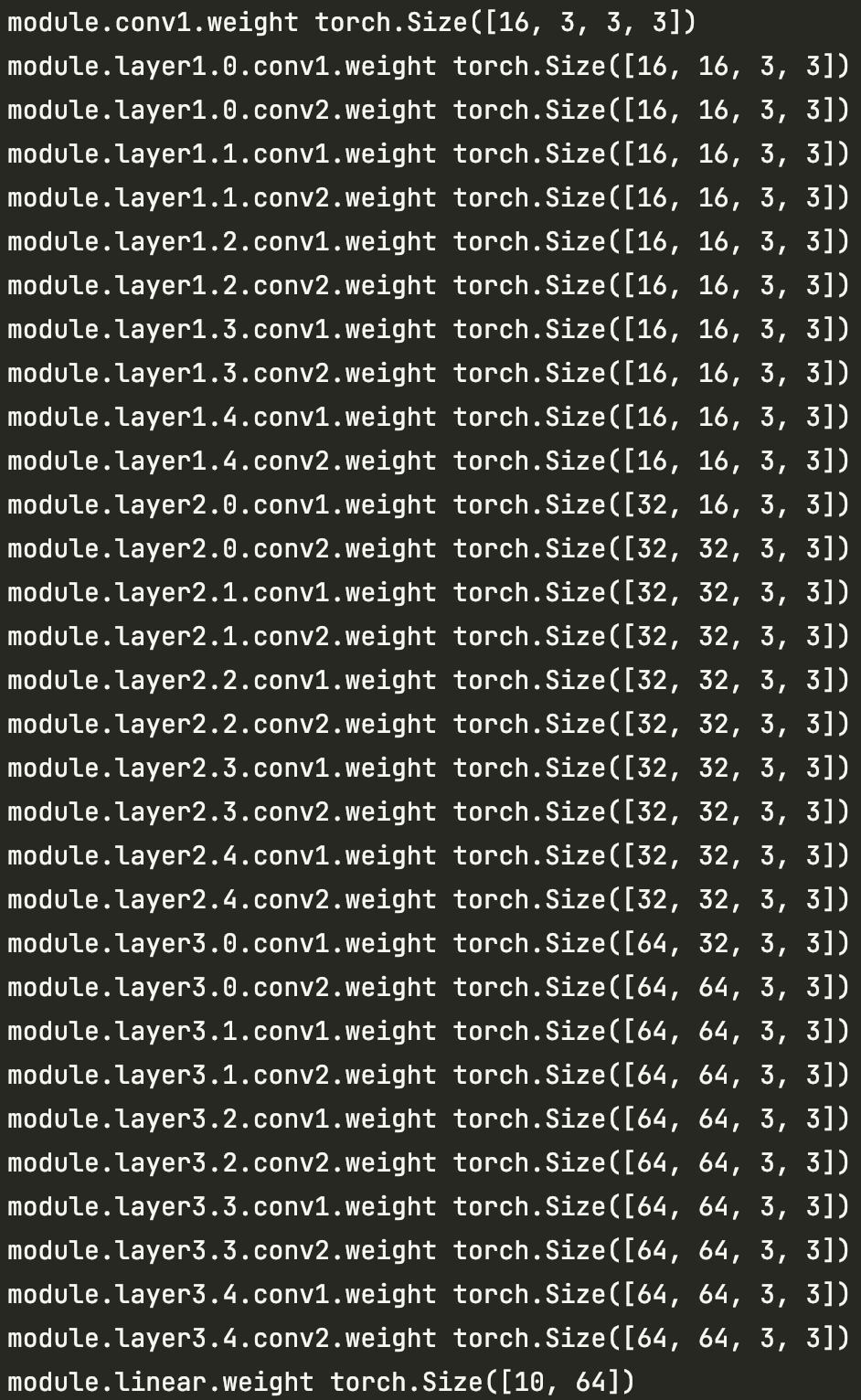
I seem to have spotted a bug in pytorch 1.9 (not 100% sure), I was running resnet32, it’s structure is as below:
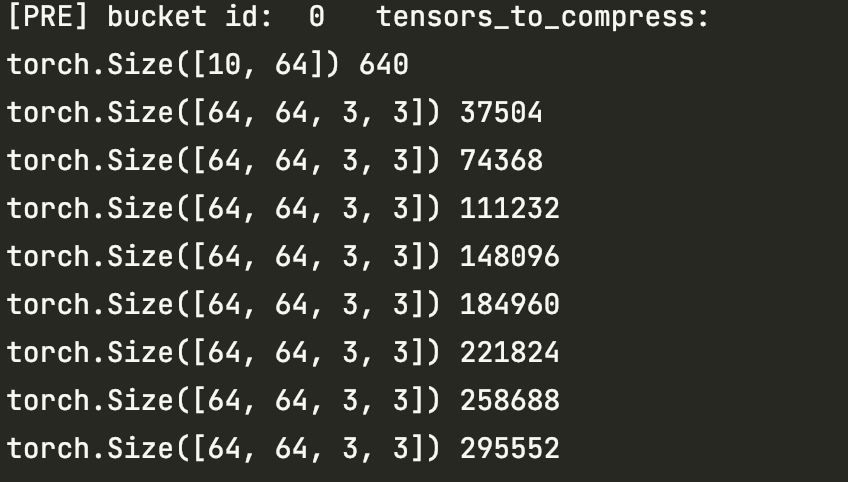
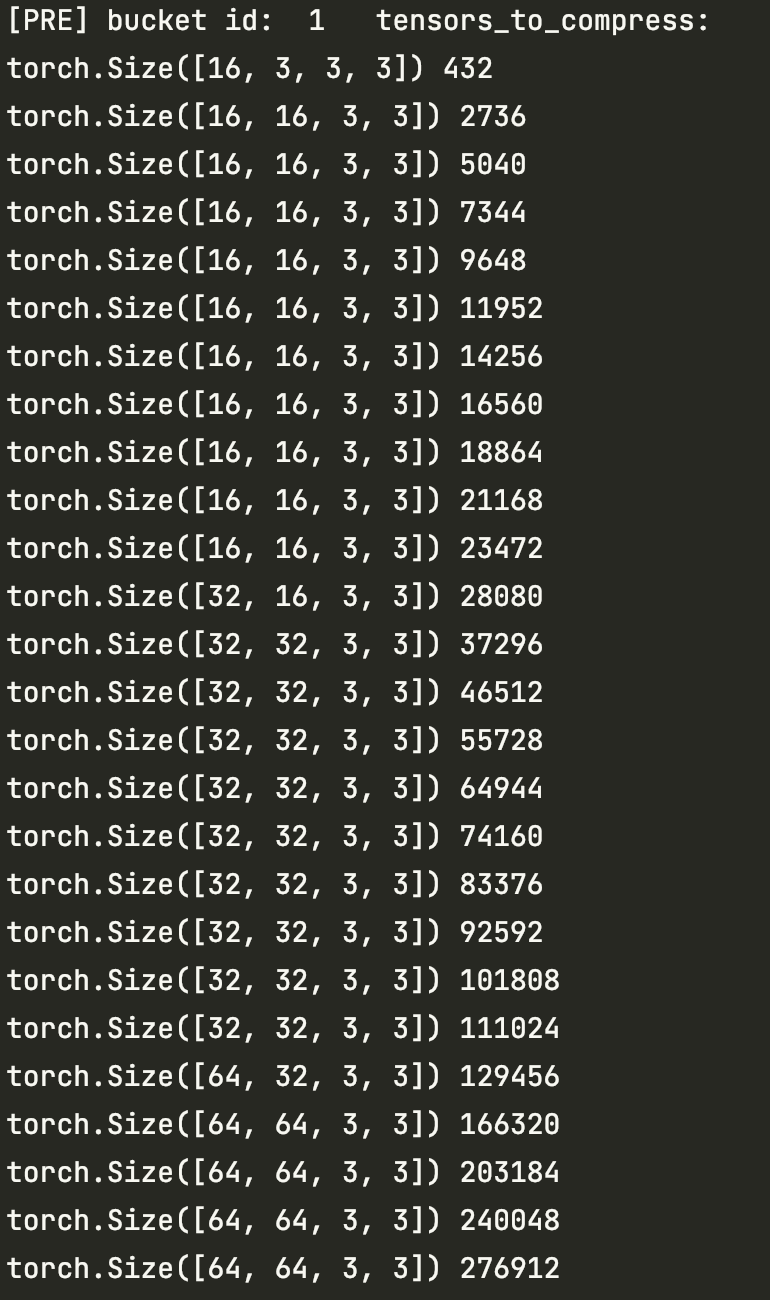
There were two buckets for this model, after the second iteration (I know buckets will be rebuilt after the first iteration, so this is the second iteration), the contents in both buckets are (bias tensor ignored):
You can see in bucket 1 the tensors are not reversed, and it falsely shared four [64, 64, 3, 3] tensors with bucket 0. After the third iteration, this problem was gone: the four tensors are unique in bucket 0 and tensors in bucket 1 are correctly reversed. So this only happens in iteration 2. In pytorch 1.12, tensors are arranged correctly in iteration 2 too.