Hello All,
I am trying to apply distilation to my model. For this question purpose, I have prepared toy example, and was wondering, why it behaves on a different ways:
- first example i am getting additional hidden output explicitly
- second example i am getting additional hidden output by setting hook-function there.
My expectation is that both of them should give the same results.
The question is:
Please could someone explain, whats wrong (it it is) with hook way for getting hidden output?
# common inputs and initial data
import torch
import torch.nn.functional as F
from torch import nn, optim
from matplotlib import pyplot as plt
x = torch.randn(10, 10)
y = torch.randn(10, 10)
First example:
# getting hidden output explicitly
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
self.fc1 = nn.Linear(10, 64) # hidden layer for getting output
self.fc2 = nn.Linear(64, 10)
def forward(self, x):
x1 = F.relu(self.fc1(x))
x = self.fc2(x1)
return x, x1
model = MyModel()
optimizer = optim.SGD(model.parameters(), lr=1e-0)
criterion = nn.MSELoss()
losses = []
for epoch in range(100):
optimizer.zero_grad()
output, aux = model(x)
loss = criterion(output, y)
loss = loss + (aux**2).mean()
losses.append(loss.item())
loss.backward()
optimizer.step()
Second example:
class MyDistilModel(nn.Module):
def __init__(self):
super(MyDistilModel, self).__init__()
self.fc1 = nn.Linear(10, 64) # the same hidden layer for getting output
self.fc2 = nn.Linear(64, 10)
def forward(self, x):
x1 = F.relu(self.fc1(x))
x = self.fc2(x1)
return x
d_model = MyDistilModel()
d_optimizer = optim.SGD(d_model.parameters(), lr=1e-0)
criterion = nn.MSELoss()
hidden = None # will collecting hidden output here
def hook(module, input_, output):
global hidden
hidden = output
lyrs = []
for l in d_model.children():
lyrs.append(l)
print(l)
lyrs[0].register_forward_hook(hook) # setting hook to the very first layer
d_losses = []
for epoch in range(100):
d_optimizer.zero_grad()
output = d_model(x)
loss = criterion(output, y)
loss = loss + (hidden**2).mean()
loss.backward()
d_optimizer.step()
d_losses.append(loss.item())
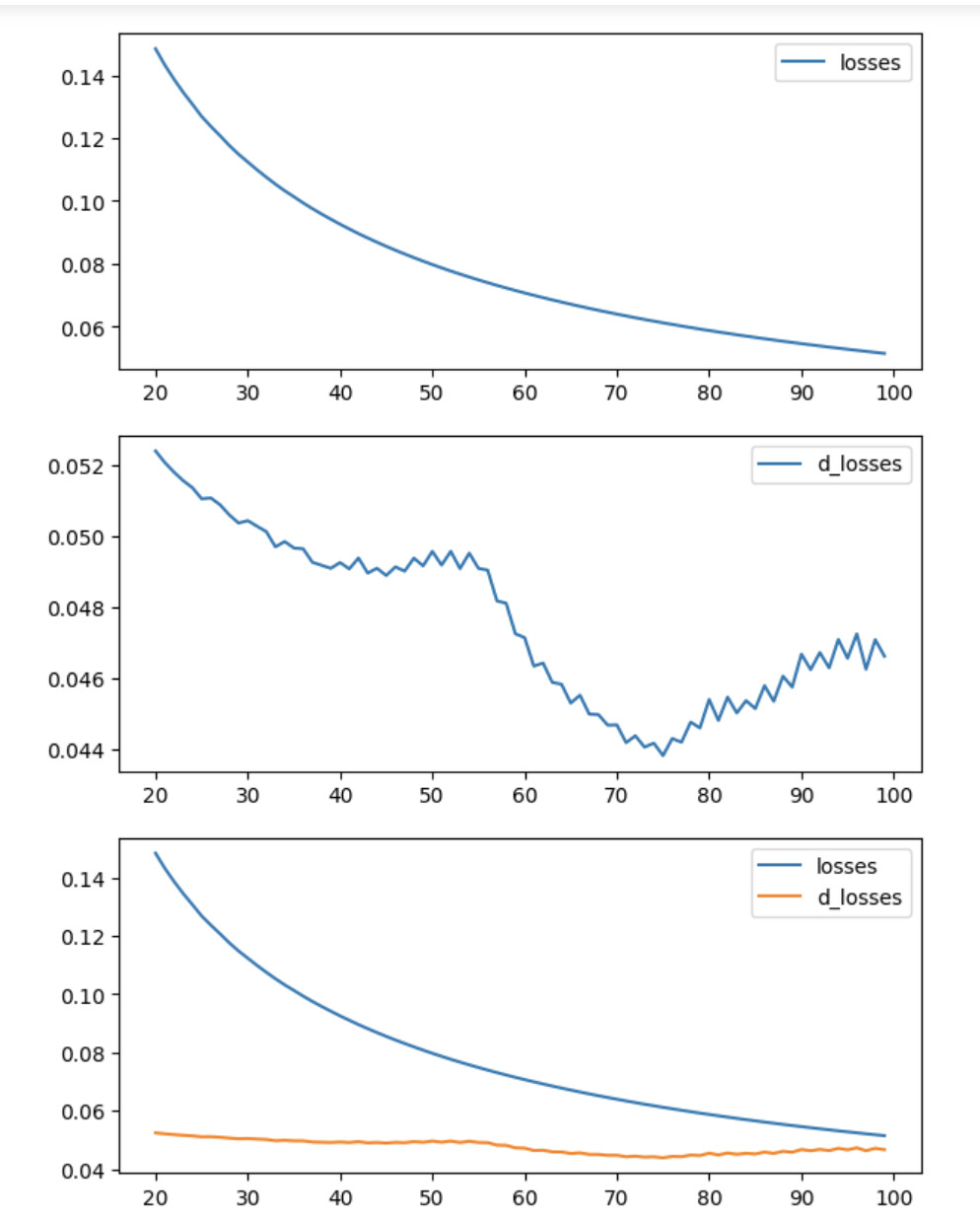
Here the visualization of losses and d_losses difference
f, (ax1, ax2, ax3) = plt.subplots(3,1)
f.set_figheight(10)
f.set_figwidth(7)
ax1.plot(list(range(100))[20:], losses[20:], label = 'losses')
ax2.plot(list(range(100))[20:], d_losses[20:], label = 'd_losses')
ax3.plot(list(range(100))[20:], losses[20:], label = 'losses')
ax3.plot(list(range(100))[20:], d_losses[20:], label = 'd_losses')
ax1.legend()
ax2.legend()
ax3.legend()
Upd.
Actually i have fixed it. The difference between two examples was in a point for getting hidden output. So in first example, F.ReLU(x) was additional applied to getting x1. So examples are not the same. After fixed it, it gives the same results