Hi, I’m currently studying pytorch DDP with 8 gpus.
I’m trying to train & validate the model with multi-gpus, and the training seems to work fine.
But in the validation phase, I tried to gather the validation output into rank 0 and print the validation accuracy and loss.
It worked, but when dist.all_gather_object is activated, I find that 7 processes are created additionally.
I think there are some inefficiency in my code.
So my questions would be:
- Why so much processes are created when I tried to gather values from each gpus?
- How to gather results from each gpu to rank 0 properly?
- Am I using DDP appropriatly & efficiently?
These are my code for each epoch and GPU status:
for epoch in range(args.epochs):
# we have to tell DistributedSampler which epoch this is
# and guarantees a different shuffling order
train_loader.sampler.set_epoch(epoch)
train_loss, train_acc = train(model, train_loader, criterion, optimizer, rank, args)
val_acc, val_loss = valid(model, val_loader, criterion, rank, args)
## gather
g_acc, g_loss = torch.randn(world_size), torch.randn(world_size)
dist.all_gather_object(g_acc, val_acc)
dist.all_gather_object(g_loss, val_loss)
if rank == 0:
val_acc, val_loss = g_acc.mean(), g_loss.mean()
print(f"EPOCH {epoch} VALID: acc = {val_acc}, loss = {val_loss}")
if val_acc > best_acc:
save_ckpt({
"epoch": epoch+1,
"state_dict": model.module.state_dict(),
"optimizer": optimizer.state_dict(),
"scheduler": scheduler.state_dict(),
}, file_name=os.path.join(args.exp, f"best_acc.pth"))
if val_loss < best_loss:
save_ckpt({
"epoch": epoch+1,
"state_dict": model.module.state_dict(),
"optimizer": optimizer.state_dict(),
"scheduler": scheduler.state_dict(),
}, file_name=os.path.join(args.exp, f"best_loss.pth"))
save_ckpt({
"epoch": epoch+1,
"state_dict": model.module.state_dict(),
"optimizer": optimizer.state_dict(),
"scheduler": scheduler.state_dict(),
}, file_name=os.path.join(args.exp, f"last.pth"))
scheduler.step()
dist.barrier()
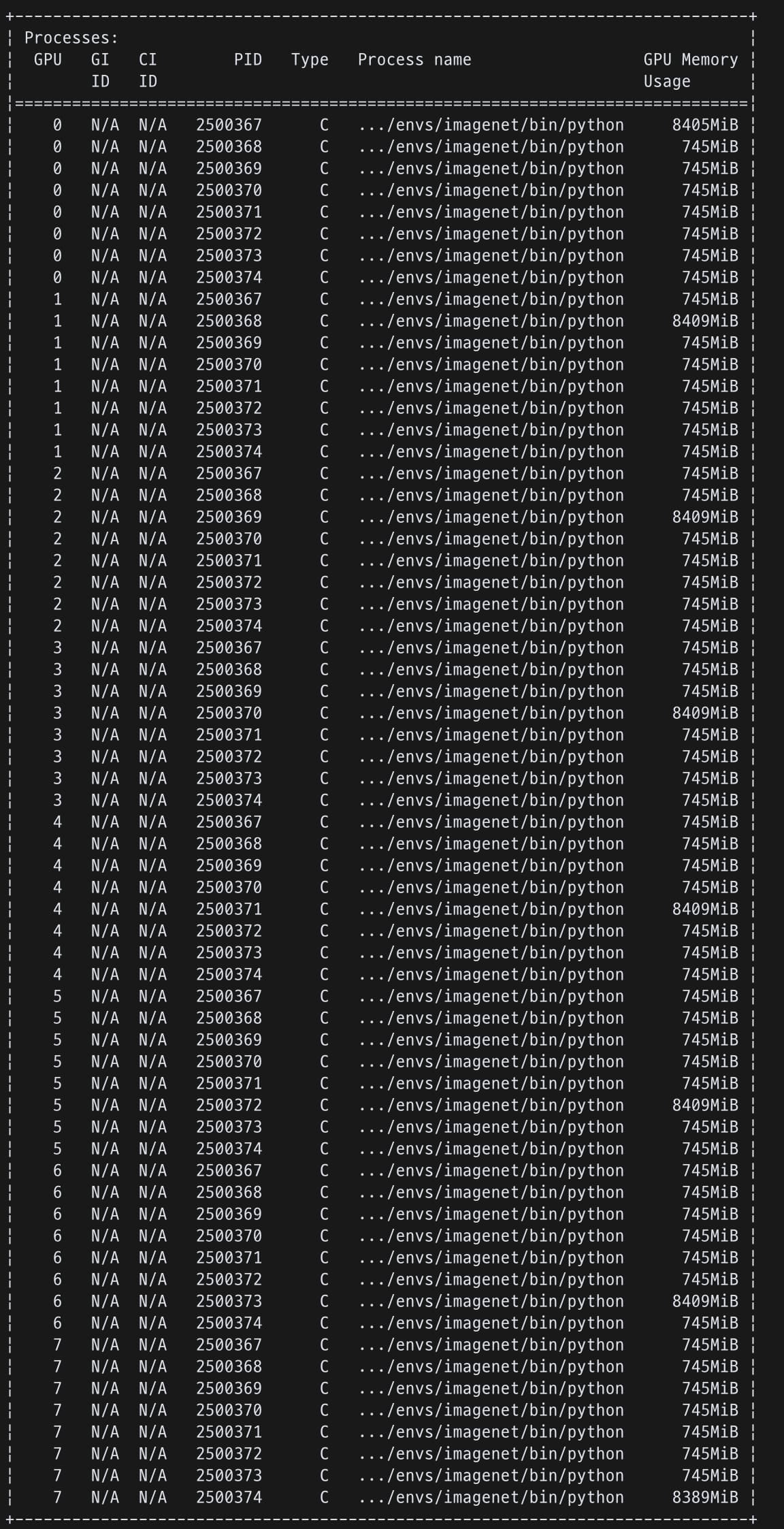
Thanks for read!