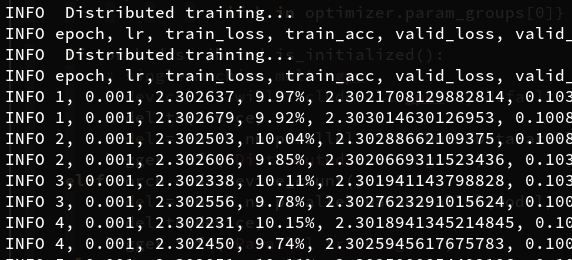
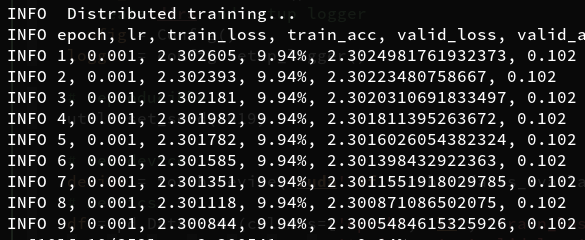
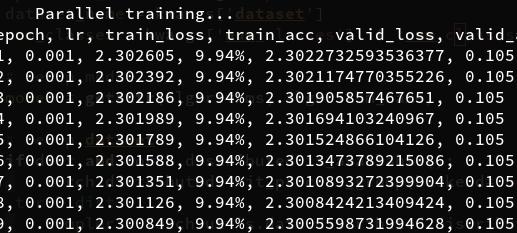
I’ve come up across this strange thing where in a simple setting training vgg16 for 10 epochs is fater with data parallel than distributed data parallel.
![]()
![]()
MWE:
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = vgg16(...)
if dist and torch.distributed.is_available():
torch.distributed.init_process_group(backend='nccl', init_method='env://')
sampler = torch.utils.data.distributed.DistributedSampler
else:
sampler = torch.utils.data.SubsetRandomSampler
db = Datasets(workers=4, pin_memory=True, sampler=sampler)
optimizer = Adam()
if torch.distributed.is_initialized():
model.to(device)
model = torch.nn.parallel.DistributedDataParallel(model)
elif torch.cuda.device_count() > 1:
model = torch.nn.parallel.DataParallel(model)
model.to(device)
else:
model.to(device)
training loop.....
Launching distributed training with
python -m torch.distributed.launch main.py
The docs identify 2 cases.
- Single-Process Multi-GPU
- Multi-Process Single-GPU
I believe that my code fall under 1.
But to achieve 2. which says is faster it describes the following changes that should be made
torch.distributed.init_process_group(backend='nccl', world_size=4, init_method='...')
model = DistributedDataParallel(model, device_ids=[i], output_device=i)
My understanding is that I should change the following in my code
torch.distributed.init_process_group(backend='nccl', init_method='env://')
into
torch.distributed.init_process_group(backend='nccl', world_size=4, init_method='...')
So far so good.
But, I’m lost in this line
model = DistributedDataParallel(model, device_ids=[i], output_device=i)
In the docs it says that i corresponds to a particular gpu.
Suppose we have 2 gpus for the sake of example and I want to run the above MWE (moved into file main.py).
Usually I would run main.py using something like python -m torch.distributed.launch main.py --i=1.
Now my confusion arises from i which only specifies one of the 2 available gpus, how’s that distributed training? Or should I specify --i=[0, 1]?
Any clarifications or pointers to mistakes or misunderstandings that I’ve made are highly appreciated it.
Thanks.