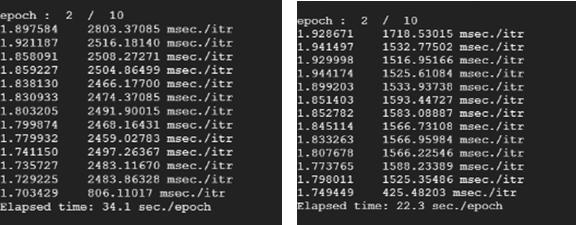
I share here two lists of codes to reproduce the issue. The first one is a program with DP, which is provided for comparison. The second one is with DDP, which takes longer for forward and backward path than DP.
DP
""" Training Resnet34 for Cifar10 by Data Parallel """
from __future__ import print_function
import torch
import torch.nn as nn
import torch.optim as optim
import torch.backends.cudnn as cudnn
import torchvision
import torchvision.transforms as transforms
import sys
import time
import argparse
from models import *
from sync_batchnorm import convert_model, DataParallelWithCallback
def main() :
parser = argparse.ArgumentParser(description='PyTorch CIFAR10 Training')
parser.add_argument('--net', default='res34')
parser.add_argument('--batch_size', default=4096)
parser.add_argument('--optimizer', default="Adam")
parser.add_argument('--epochs', default=2)
parser.add_argument('--n_nodes', default=1)
parser.add_argument('--nr', default=0)
args = parser.parse_args()
if torch.cuda.is_available() :
args.n_gpus = torch.cuda.device_count()
print(args.n_gpus, " GPU(s) available")
print(torch.cuda.get_device_name(0))
else :
print("GPU is NOT available.")
sys.exit()
print("Total batch size = ", args.batch_size)
print("Batch size = ", int(args.batch_size / args.n_gpus), "/ GPU")
print("Optimizer = ", args.optimizer)
train(args)
print()
# Training
def train(args):
epochs = args.epochs
batch_size = args.batch_size # total batch_size.
n_gpus = args.n_gpus
worker = 8
if args.net=='res18':
net = ResNet18()
elif args.net=='res34':
net = ResNet34()
elif args.net=='res50':
net = ResNet50()
elif args.net=='res101':
net = ResNet101()
print("Model = ", net.__class__.__name__)
print()
d_list = list(range(n_gpus))
net = convert_model(net).cuda() # Convert BatchNorm into SyncBatchNorm
net = DataParallelWithCallback(net, device_ids = d_list) # Data Parallel
cudnn.benchmark = True
criterion = nn.CrossEntropyLoss()
if args.optimizer == "Adam" :
optimizer = optim.Adam(net.parameters())
elif args.optimizer == "SGD" :
optimizer = optim.SGD(net.parameters(), lr = 0.1)
transform_list = [
transforms.RandomChoice([
transforms.RandomCrop(32, padding=4),
transforms.RandomResizedCrop(32, scale=(0.7, 1.0), ratio = (1.0, 1.0)),
]),
transforms.RandomHorizontalFlip(),
transforms.RandomRotation(degrees = 20),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
]
transform_train = transforms.Compose(transform_list)
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform_train)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=batch_size, shuffle=True, num_workers=worker)
for epoch in range(epochs):
print()
print("epoch : ",epoch + 1, " / ", epochs)
net.train()
""" ------- Training loop -------- """
for batch_idx, (inputs, targets) in enumerate(trainloader):
inputs, targets = inputs.to('cuda'), targets.to('cuda')
message = ""
t0 = time.time()
optimizer.zero_grad()
t1 = time.time()
message += " zero grad: {0:.5f}".format(t1 - t0)
outputs = net(inputs)
t2 = time.time()
message += " out: {0:.5f}".format(t2 - t1)
loss = criterion(outputs, targets)
t3 = time.time()
message += " loss: {0:.5f}".format(t3 - t2)
loss.backward()
t4 = time.time()
message += " back: {0:.5f}".format(t4 - t3)
loss_val = optimizer.step(loss.item) # loss value is given through optimizer.
t5 = time.time()
message += " step: {0:.5f}".format(t5 - t4)
print("{0:.6f}".format(loss_val) + message)
if __name__ == '__main__':
main()
DDP
""" Training Resnet34 for Cifar10 by Distributed Data Parallel """
from __future__ import print_function
import torch.multiprocessing as mp
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDP
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import torch.backends.cudnn as cudnn
import torchvision
import torchvision.transforms as transforms
import sys
import os
import time
import argparse
from models import *
from sync_batchnorm import convert_model, DataParallelWithCallback
def main() :
parser = argparse.ArgumentParser(description='PyTorch CIFAR10 Training')
parser.add_argument('--net', default='res34')
parser.add_argument('--batch_size', default=4096)
parser.add_argument('--optimizer', default="Adam")
parser.add_argument('--epochs', default=1)
parser.add_argument('--n_nodes', default=1)
parser.add_argument('--nr', default=0)
args = parser.parse_args()
if torch.cuda.is_available() :
args.n_gpus = torch.cuda.device_count()
print(args.n_gpus, " GPU(s) available")
print(torch.cuda.get_device_name(0))
# for DDP
args.world_size = args.n_gpus * args.n_nodes
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '8888'
else :
print("GPU is NOT available.")
sys.exit()
print("Total batch size = ", args.batch_size)
args.batch_size = int(args.batch_size / args.world_size) # for DDP
print("Batch size = ", args.batch_size, "/ GPU")
print("Optimizer = ", args.optimizer)
""" Distributed Data Parallel (DDP)"""
mp.spawn(train, nprocs=args.n_gpus, args=(args,))
print()
# Training
def train(gpu, args):
rank = args.nr * args.n_gpus + gpu
dist.init_process_group(
backend='nccl',
init_method='env://',
world_size=args.world_size,
rank=rank
)
epochs = args.epochs
batch_size = args.batch_size # batch_size is per GPU size.
torch.manual_seed(0)
if args.net=='res18':
net = ResNet18()
elif args.net=='res34':
net = ResNet34()
elif args.net=='res50':
net = ResNet50()
elif args.net=='res101':
net = ResNet101()
if rank == 0 :
print("Model = ", net.__class__.__name__)
print()
torch.cuda.set_device(gpu)
net = torch.nn.SyncBatchNorm.convert_sync_batchnorm(net)
net = net.cuda(gpu)
criterion = nn.CrossEntropyLoss().cuda(gpu)
if args.optimizer == "Adam" :
optimizer = optim.Adam(net.parameters())
elif args.optimizer == "SGD" :
optimizer = optim.SGD(net.parameters(), lr = 0.1)
net = nn.parallel.DistributedDataParallel(net, device_ids=[gpu])
transform_list = [
transforms.RandomChoice([
transforms.RandomCrop(32, padding=4),
transforms.RandomResizedCrop(32, scale=(0.7, 1.0), ratio = (1.0, 1.0)),
]),
transforms.RandomHorizontalFlip(),
transforms.RandomRotation(degrees = 20),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
]
transform_train = transforms.Compose(transform_list)
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform_train)
train_sampler = torch.utils.data.distributed.DistributedSampler(
trainset,
num_replicas = args.world_size,
rank = rank
)
trainloader = torch.utils.data.DataLoader(trainset, batch_size = batch_size,
shuffle=False, num_workers=0,
pin_memory = False, sampler=train_sampler)
for epoch in range(epochs):
if rank == 0 :
print()
print("epoch : ",epoch + 1, " / ", epochs)
net.train()
""" ------- Training loop -------- """
for batch_idx, (inputs, targets) in enumerate(trainloader):
inputs = inputs.cuda(non_blocking=True)
targets = targets.cuda(non_blocking=True)
message = ""
t0 = time.time()
optimizer.zero_grad()
t1 = time.time()
message += " zero grad: {0:.5f}".format(t1 - t0)
outputs = net(inputs)
t2 = time.time()
message += " out: {0:.5f}".format(t2 - t1)
loss = criterion(outputs, targets)
t3 = time.time()
message += " loss: {0:.5f}".format(t3 - t2)
loss.backward()
t4 = time.time()
message += " back: {0:.5f}".format(t4 - t3)
loss_val = optimizer.step(loss.item) # loss value is given through optimizer.
t5 = time.time()
message += " step: {0:.5f}".format(t5 - t4)
if rank == 0 :
print("{0:.6f}".format(loss_val) + message)
dist.destroy_process_group()
if __name__ == '__main__':
main()
Please let me know if something is wrong. Thank you.