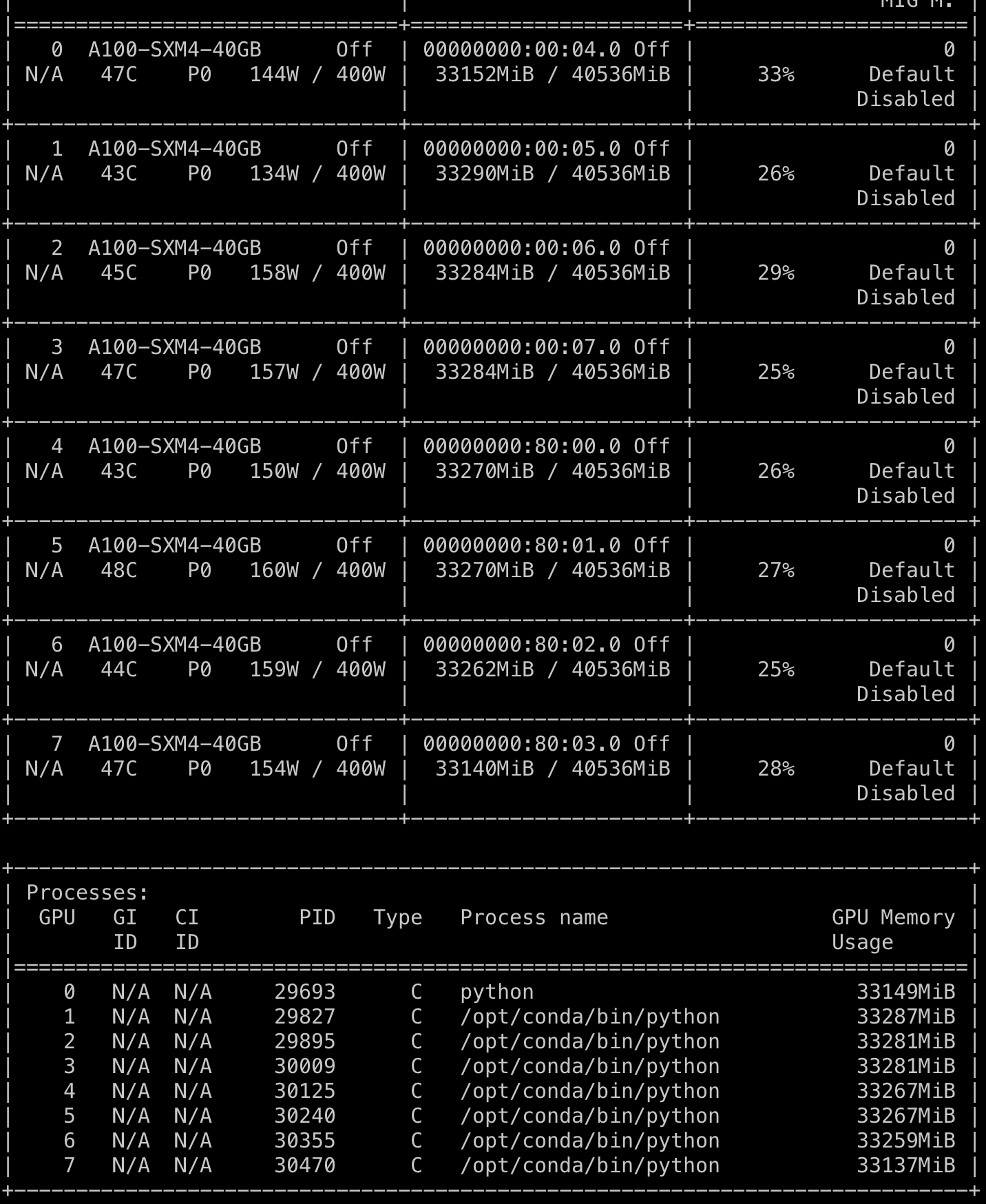
I’m using DDP for training (using DDP wrapper around the model) and when I spawn n jobs I see the process on with nvidia-smi/gpustat but then there are (n-1) other GPU processes that are also created. I’m guessing that these are for communication between gpu0 and the other processes. I don’t see anything in the documentation or this forum about that. Below is output from gpustat for a 2 GPU job. The 2 GPU process using memory 9763 are the model and then there is 565M size process on gpu0. The latter process seems to be about the same size for any model.
Could you please check the process ids? Each DDP process is supposed to only work on one device. Suppose the expected case is process rank 0 on cuda:0 and process rank1 on cuda:1. It’s likely that somehow process rank1 also created a CUDA context on cuda:0. The size of 565M also looks like a CUDA context.
If it’s indeed the case, there are a few actions can help avoid such problem:
Run torch.cuda.set_device(rank) on each process to properly set the current device before running any CUDA ops.
If 1 still does not solve the problem, you can set CUDA_VISIBLE_DEVICES env var to make sure that process 0 only sees gpu0 and process 1 only sees gpu1.
I was seeing the same issue with multi gpu training(DDP strategy). n-1 extra processes on each gpu holding ~1400MiB on A100 Gpus.
I zeroed down the issue to pytorch-lightning's Trainer() flag auto_select_gpus=True. Setting it to False solve the issue. Now I can train with larger batch size to fully utilize the gpu memory when I want to.