I was looking into training machine learning models in multiple cores. To be more clear, suppose I have “N” machine learning units (for eg. three layered neural network [in-hid-out] ). Each of the units are identical to each other. However, I want to train each network with different input of same nature (for eg. If I have 10 machine learning units with MNIST data as input, each of the 10 units will be trained on different sets of data). You can think of it as training the networks with MNIST in 10 geographically dispersed location where we are not sure which network will have what set of inputs. However, at somepoint I want to communicate between the machine learning models while updating the weights. I want to distribute same weights to all the models. For people who know federated learning, its like applying federated learning in multiple CPU/GPU cores.
Is it possible to do something like this in multiple cores of a CPU or GPU? Or is there any documentation that you can provide me?
I am not sure what to call this. But its kind of distributed training where each of the neural network in different processes communicate while updating the weight. Would the approaches you provided do the same?
P.S. I don’t want to distribute a single set of input to multiple nodes/processes. Suppose I have 2 nodes N1 and N2, then I need to send a set of input for N1 and another set of input for N2, which is different than the set for N1 (and not collected in batches from a common data set). I am not sure if I explained it correctly. Sorry about that.
But its kind of distributed training where each of the neural network in different processes communicate while updating the weight
Does it have to communicate parameters instead of gradients? If all you need is to keep the parameters on all processes in sync, communicating gradients should be sufficient I think.
I don’t want to distribute a single set of input to multiple nodes/processes.
Yep, DDP does not split inputs, instead each process need to prepare its own inputs.
One question is, does the parameters/gradients communication occur in a synchronized or asynchronized fashion? “Synchronized” means all processes communicate at exactly the same time, while asynchronized can be something like gossip. DDP only works for synchronized use cases. If you need asynchronized communication, you can directly use c10d (allreduce, allgather, broadcast, etc.) and create multiple sub-groups to perform communicatioin.
I am not a Machine Learning savvy, so please mind the errors while I write this:
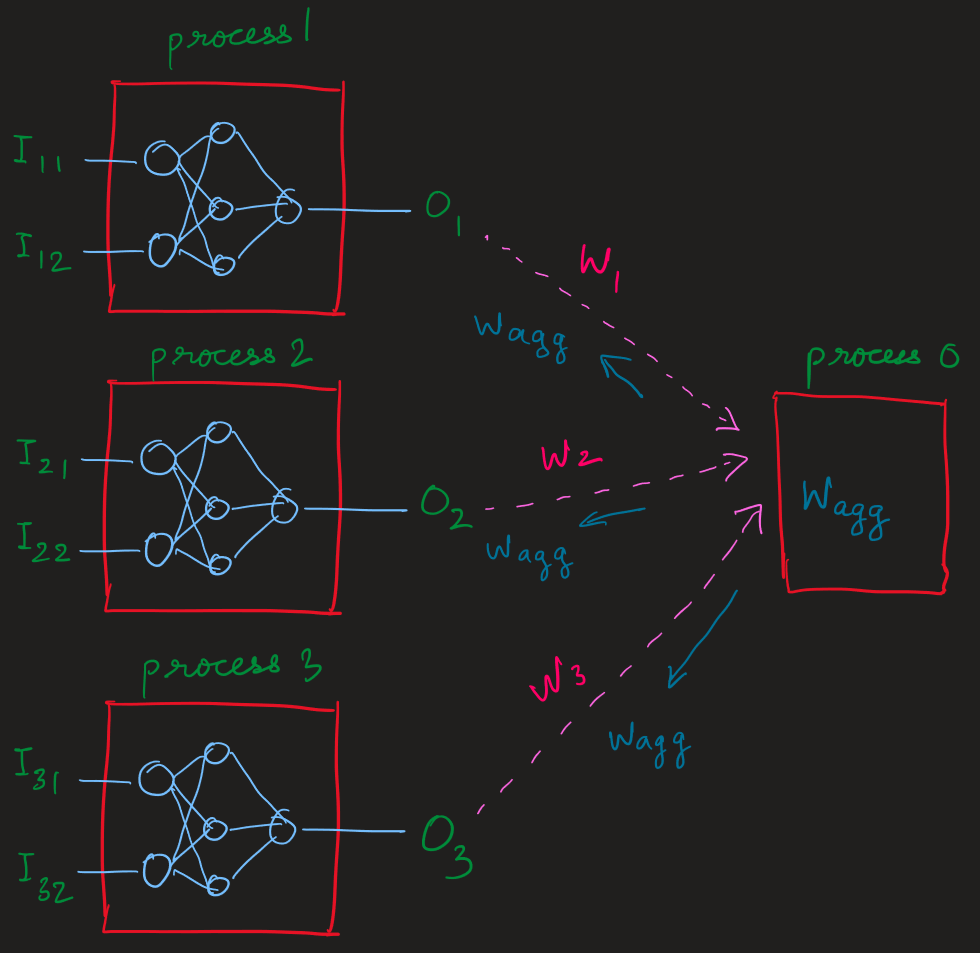
I think the figure will explain this right. Since I will be gathering the weights of all the networks residing at different processes, I need to pass the weight parameters right? And the weight gathering needs to happen asynchronously, at different point of time. But to get a start, at this point, we can assume that the weight gathering happens synchronously, at the same point of time.
Furthermore, the gathered weights need to be averaged at the root process and the aggregated weight should be broadcasted again to the networks for next epoch. I am not sure if you get this due to my weird way of explaining things but thanks for being modest and replying promptly.
If you could tell me a specific way to handle this, I could narrow down my scope of researching the documents and tutorials. Thank you again.
Based on the diagram and explanations, it seems like you are trying to train the network, with each node training on its own data, and ensuring that the parameters stay in sync across all the nodes. If this is the case, you will want to communicate the gradients, and not the weights.
DDP works perfectly for synchronous distributed training. Each node will independently perform the forward and backward pass on its own batch of data. Then, each node will send its computed gradients to every other node. Once each node has the gradients for all other nodes, they will independently average all the gradients and run the optimizer to perform the gradient update. One note is that there is no “root” process responsible for aggregating the gradients (what you’re describing is similar to a parameter server). In DDP, the nodes communicate with each to exchange gradients.
For asynchronous distributed training, you can use the c10d communication primitives as @mrshenli described above.