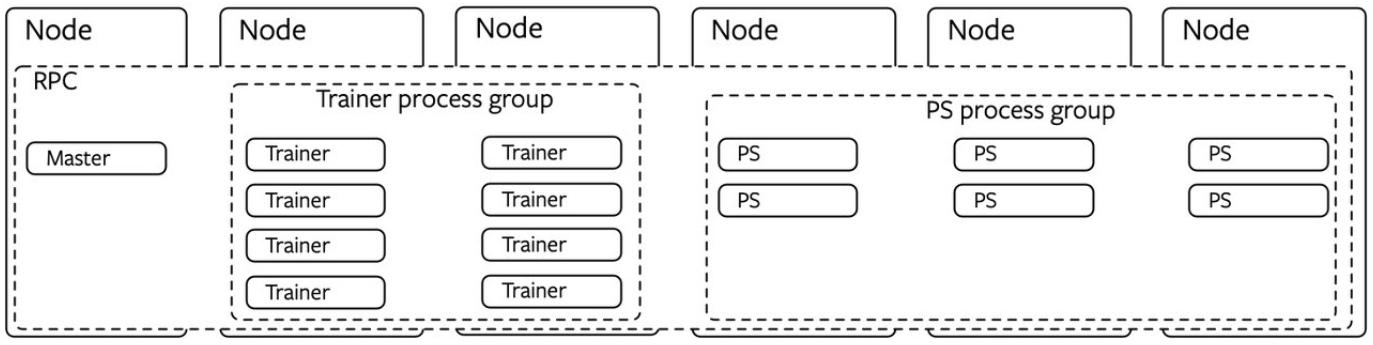
I have a question when we have to scale the model into multiple machines.
Think of an instance where we have 16 layers (L1 — L16) where we have 4 machines each with 4 GPU devices. So my model will scale into all 16 GPUs in 4 machines such that each layer occupies the memory of a one GPU device. Assume a theoretical scenario memory is enough for computation.
When I need to do such a task, my training script must be written in such a way that if the original model was M, now I have M1 – M16 smaller models which depends upon the output of the previous model in the sequence.
I am not sure whether this is the best way to do this. If this is wrong, please explain the best practices with the RPC API.
Furthermore, here M1–M4 makes sense and that can be done by to(device) and when I have to send the input from M4 to M5, M4 is in GPU:3 of machine 1, M5 is in the GPU:0 of machine 2, I need to some how use an RPC call and send that data to the machine 2. This is the same case for all boundary conditions. Data could be sent some how via a synchronization mechanism.
Is this something possible with the existing APIs. I am not quite clear how DistributedOptimizer and Distributed Autograd could handle this.
These are some questions I have about the distributed model parallel.
Hey @Vibhatha_Abeykoon, thanks for the question, this actually relates to several WIP projects that we are working on now.
When I need to do such a task, my training script must be written in such a way that if the original model was M, now I have M1 – M16 smaller models which depends upon the output of the previous model in the sequence.
In this case, you need 4 instead of 16 smaller models, and within each model you can use Tensor.to(device) to move data across GPUs as you mentioned below. For pipeline parallelism using RPC, this tutorial can serve as a reference (will be released with v1.6).
I am not sure whether this is the best way to do this. If this is wrong, please explain the best practices with the RPC API.
This is not the most convenient way to support pipeline parallelism. RPC is a lower-level API that offers flexibility but would require additional application code to orchestrate. One of the projects that we are looking into is to provide a higher-level API, e.g., a DistributedPipelineParallel (DPP) (similar to the DistributedDataParallel) which, ideally, can automatically divide the original model and place model shards (maybe) by using additional configuration hints or specific model structure (e.g., nn.Sequential). But this is still in discussion and no committed release date for it yet. Please do comment if you have suggestions or requirements on this feature.
I need to some how use an RPC call and send that data to the machine 2. This is the same case for all boundary conditions.
If you want the distributed autograd to automatically take care of the backward pass across machines, then yes, you will need to use RPC to send the intermediate output form machine 1 to machine 2. As of v1.6, RPC only accepts CPU tensors, so you will need to first move the tensor from cuda:3 to cpu on machine 1 and then move the received tensor from cpu to cuda:0 on machine 2. We explicitly added this restriction to avoid unintentional device mapping errors through RPC. And we are working on a new device placement API (similar to the map_location in torch.load) to make this easier, where application can define default device mappings between each pair of nodes and directly pass GPU tensors to RPC. We hope we can get this done in v1.7.
Data could be sent some how via a synchronization mechanism.
What do you mean by “a synchronization mechanism” here?
Is this something possible with the existing APIs. I am not quite clear how DistributedOptimizer and Distributed Autograd could handle this.
@mrshenli This tutorial is wonderful. I was writing one and I think I can learn a lot from yours. I had questions when I was attempting this.
What I meant from synchronization is as the Model-Shard in Machine 1 needs to complete compute to start the Model-Shard2, even in pipeline case. Please correct me if I am wrong.
So the Machine 2 Model-Shard2 must wait, until it gets the weights from Machine 2. And again, I am still going through your tutorial and may have answers in there.
One more thing, is how are we deploying this multi-machine model parallel module?
Will there be modifications to torch.distributed.launch? What is the current method to launch this
as we do for DDP?
The Pipeline parallel API would be just great. I was attempting to wrap this with Torchgpipe or Pipedream and I also felt like it is better if it can come within the PyTorch APIs.
I have a few suggestions, if we can make use of to(device) call into to(machine:device) kind of an API endpoint, it will be much easier to work, but I am not quite sure how the changes should reflect internally.
The DPP module needs a few features.
How to partition the model, (a profiler based auto-partitioned or a manual one so that user can say how to partition). Model partition in a manual way and saying .to(device) is not going to work when we have to deal with complex and large models. So if this could be handled internally, it will be ideal for all users.
From the knowledge of using Torchgpipe, Rematerialization as a custom option within DPP would be a great option. There are couple reasons for this, some applications need performance using pipelining rather than saving memory. So in this case one could have the ability to turn it off and on depending on the training job. DPP could have a flag rematerialztion=False/True to make it disabled or enabled for the user.
With the Pipedream work, it was very clear that the multi-machine involvement could be very useful for training and their profiler usage is important in getting a better DPP.
Enabling checkpointing internally for DPP would be easier as handling this manually could be troublesome. When the shards are distributed across machines the checkpoint itself needs to be a distributed entity (in my understanding).
These could be great additions to DPP if possible.
Yep, this is correct. That tutorial uses RRef.to_here() to block wait for the result. The downside is that this would block one RPC thread until to_here() returns. If this is a concern, the async_execution decorator can help. [tutorial]
One more thing, is how are we deploying this multi-machine model parallel module?
Will there be modifications to torch.distributed.launch? What is the current method to launch this
as we do for DDP?
I have a few suggestions, if we can make use of to(device) call into to(machine:device) kind of an API endpoint, it will be much easier to work, but I am not quite sure how the changes should reflect internally.
Right! This aligns with the remote device feature that we would love to build on top of RPC, but we don’t have bandwidth to cover that yet. It won’t be very hard to convert every operation of a remote device tensor into an RPC invocation, however that will be too slow due to the per-op comm overhead. Ideally, we should have a remote Tensor type that can do op fusing when possible, similar to lazy tensor. But as this would require a lot of effort and we haven’t seen too many requests for this yet, this feature didn’t make into our top priorities for now. We will come back to re-evaluate after the next release.
How to partition the model, (a profiler based auto-partitioned or a manual one so that user can say how to partition). Model partition in a manual way and saying .to(device) is not going to work when we have to deal with complex and large models. So if this could be handled internally, it will be ideal for all users.
With the Pipedream work, it was very clear that the multi-machine involvement could be very useful for training and their profiler usage is important in getting a better DPP.
Thanks a lot for all the suggestions!! Totally agree. Profiling is great and can definitely provide an easier entry point, especially when the application does not need to squeeze out the last bit of performance. For more perf-centric use cases, we might still want to allow users to hand-craft model partitioning and placement, maybe, by accepting some hints/configs.
Enabling checkpointing internally for DPP would be easier as handling this manually could be troublesome. When the shards are distributed across machines the checkpoint itself needs to be a distributed entity (in my understanding).
Exactly, this is a feature gap in RPC. We might be able to add checkpointing support to the WIP RemoteModel feature and build DPP on top.
@mrshenli Thank you so much for this detailed explanation. I will try to design on top of what is offered from the PyTorch APIs. The plan you suggested is great and hope to use these in near future.
Just following up with you based on the performance factor.
For distributed model parallelism, could MPI-collective communication be a better choice than distributed RPC? I mean these are two different models designed to serve two different purposes. But, at the end of the day what we would be doing is sending or receiving data from one point to another point. In terms of performance does PyTorch Distributed RPC outperforms MPI-Collectives (especially ISend/IRecv, Send/Recv)? Is this something PyTorch community already considered and decided to go with RPCs instead of MPI libraries?
But I understand the currently distributed optimizer, Autograd and those extensible components have been written to support RPC. But does MPI stand a chance here?
We will announce a new RPC backend in v1.6, which is called TensorPipe. This is a P2P comm library and is designed to automatically figure out the best comm media between two RPC workers, e.g., shm, tcp, nvlink, ib, etc. (This is still WIP) We will gradually make TensorPipe the default RPC backend and retire ProcessGroup RPC backend due to the perf reasons as you noticed. The original reason for adding ProcessGroup RPC backend is to have a working comm module to unblock other parts of the system, and also buy us time to design better solutions.
Regarding MPI, we probably will not develop an RPC backend on top of MPI but we do welcome OSS contributions or it might be possible to add MPI as a channel type in TensorPipe. One downside of using MPI is that there are different implementations does not seem to be one implementation that rules all use cases. That’s also one reason why PyTorch does not include MPI as a submodule but require the users to provide a MPI installation and compile from source.
Is there any specific reason for requesting MPI RPC backend?
The main reason is that there are tons of Scientific Applications written on MPI and it would be really hard to port them back to a different backend. These applications will do an MPI_Init somewhere at the very beginning of the program. In the early part of the program, there are specific scientific data pre-processing, shallow/complex algorithms applied to pre-process the data. Then comes the DL workload. Such applications are very common in the high-performance computing domain. So supporting MPI-backend could be very vital to support such applications seamlessly without breaking the data pipeline/training.
I understand there are many MPI-implementations. But MPI still can be left to the user to install, but the specifications are mostly consistent in most of the MPI implementations. All it needs is a wrapper library to wrap the collective communication calls. PyTorch already has this API in C10D. Please correct me if I am wrong.
Tensorpipe seems to be a very interesting project that could glue all these together.
I see. Technically, it shouldn’t be too hard to let the ProcessGroup RPC backend to use MPI, as it only requires its send/recv features. One options could be adding one field to ProcessGroup RPC backend construction time options, and let users decide whether they want to use Gloo, or NCCL (> 2.7), or MPI.
cc @lcw any thoughts on MPI + TensorPipe? Does it make sense to add MPI as a channel type for TensorPipe?
I don’t understand the argument for using MPI in RPC: what does the fact that other libraries use the MPI API have to do with the RPC library using it under the hood? AFAIK, MPI is not incompatible with Gloo or TensorPipe: the same process can use them both, in different parts of the code. Also, the fact that RPC uses MPI internally does not help with porting MPI code to RPC: it would still have to be rewritten to use the RPC interface.
A good reason would be if there was a difference in performance. Have you reason to believe there is?
If we were stuck with the ProcessGroup agent only, then I could agree that we should allow it to use MPI instead of Gloo, but as it’s slated to go away in favor of the TensorPipe-based one this change may not end up being so useful. TensorPipe is natively asynchronous, and thus suits really well the use-case of RPC, contrary to Gloo and MPI which are blocking. We have already proven that TensorPipe outperforms Gloo for RPC. It may be different for MPI, as some MPI implementations use specialized backends, but that’s what TensorPipe is also going to do.
My two cents on the above discussion too: ideally you shouldn’t specialize your code to handle differently the transfers between GPUs on the same node and between different nodes. By doing so you couple your code with your deployment, meaning you need to rewrite some parts to change from 4 GPUs/host to single-GPU hosts and so on. With the TensorPipe agent you will be able to perform RPC calls between GPUs on a node and the data will still be transferred over NVLink just as if you had done t.to(…). So with no performance overhead you get code that is resilient to a topology change.
@lcw It is not an argument, just asking if this is something possible with the current implementations you have. With MPI asynchronous calls you can still get asynchronous attribute to the code.
Yes, we have to still re-write, but unless MPI backend support is there, the communication on RPC channels will have different performance. Have you benchmarked the performance of Gloo, TensorPipe RPC vs MPI? The reason for asking the MPI compatibility is that, a program would not only have a training script. It has a data pre-processing functions, training and post-processing based on the trained model. If a system designed with an MPI backend is used to be as the main framework where PyTorch act as a library within the code, in those cases the support from MPI is immensely important. The use cases of using PyTorch is getting complex and complex, I think that is why a library like Tensorpipe is also coming into play.
I just wanted to point out a possible usage of MPI within the distribution.
This is really useful for model parallelism and writing complex networks with feedback loops.
Is Tensor-pipe going to be a standalone library or is this going to be adopted in torch.distributed.rpc ?
MPI is not appropriate for serving as a new backend of RPC.
Their model are totally different and inherently incompatible with each other.
Now the serious explanation, to put it simply:
MPI style is tightly coupled, P2P primitives like recv, send, irecv, isend are there simply because you wouldn’t want to introduce an additional library to complete a simple P2P commnication, like collecting a state or log.
RPC style is complete decoupled, services are there and you can access it if a process want and have the permission to. Therefore synchronization becomes a disaster because processes are distributed.
Tensorpipe is mainly just a smart payload delivery layer, it is there because the important “decision” feature will greatly improve the performance of rpc, since unoptimized rpc libraries such as “GRPC”, “Dubbo” “Swift” does not handle tensors on defferent devices well. It is designed for the distributed scenario. And it can also handle elasticity and dynamic size (Eg: initialize your program with different number of process-roles, esbecially important if you want to add some springness to your application) very well, in this case, MPI is just way too rigid.
BTW, distributed applications are complex, you cannot expect pytorch to be any simpler because it is already very simple, its rpc api could be considered “overly simple and crude” if you compare it to an industrial grade rpc framework “Dubbo” designed by Alibaba:
You can use MPI to implement rpc, techincally, but the performance could be really bad, for example, in order to send a message of arbitrary length, in MPI you need to send the size to your target, then the target has to allocate the memory, then you can send the payload, since MPI is not a raw connection like tcp or infiniband, you would expect more delay in these two communications, and you have to deal with process failures! MPI will fail if any component process has failed, and that’s why we would like to remove that behavior in rpc, see 88856.
@iffiX I would like to ask you to keep the discussion objective.
If you disagree with something, explain your position and keep the discussion alive.
While the majority of your post is a great explanation, the first part is unfortunately not.
I will use “process/device” (Eg: “worker:0/cuda:0”) as a location descriptor of a tensor, and tensor is the only holder of all data.
The first thing is:
I have a primitive design for this purpose: an assigner and a simple wrapper, assigner currently won’t partition a model auto matically, instead it will just assign user specified partitions based on a series of heuristics (GPU mem, GPU power, CPU mem, CPU power, Model complexity, bandwidth of connection between models), but it could be also reworked to fulfill your purpose, and you just need to wrap all of your submodules in the wrapper, the wrapper just stores input/output location descritors, nothing more.
Simply speaking, partitioning just require users to specify the input and output (process/device) requirements for a module/model, and then a smart assigner to assign partitions to process/device.
Theoretically a dynamic profiler is much better than a static heuristic assigner, since it actively detects hotspots and try to even the load on all of your nodes, but this introduces additional issues: Is evening the load across nodes increasing the performance? How much cost have the additional transmission introduced? Is the decreasing the load not pushing your GPUs to their full capacity (kernel launching cost should be considered)? So there are possibilities that this solution does not meet with the theoretical standard.
I beilieve @mrshenli has studied about this issue, from his profile page. I think many more experiments are needed to determine the best scheme.
The second thing is:
I think it won’t be too defficult if rpc.pair in #41546 is implemented,
tensor.to("worker:1/cuda:0")
is equivalent to
# suppose there is a tensor on process "worker:0" and device "cuda:0" of this process
# move to process "worker:1" and device "cuda:1" of that process
# take care when torch.cuda.set_device is used
def pair_and_move_to(tensor, device, uuid):
# uuid should be a unique identifier to identify this tensor
# could be process_name:tensor_ptr
tensor = tensor.to(device)
rpc.pair(uuid, tensor)
return RRef(tensor)
# on worker:0 when .to is invoked:
rpc.rpc_sync("worker:1", rpc.pair, args=(tensor, "cuda:1", tensor.some_uuid))
And for implementing Distributed Model Parallel Using Distributed RPC, there are many model parallel methods, it depends on your model, algorithm framework and application. For DDP compatible RPC solutions specifically, I have implementations of a gradient reduction server in my framework, which should be able to do the exact same thing as DDP does, however, this server implementation is also based on new API RFC #41546, which haven’t been implemented in pytorch. I have made a simple wrapper upon current primitive RPC APIs for this RFC, it is not efficient since two primitive RPC requests have to be made per wrapped high level RPC API, but it is tested and workable, if you would like to take a look.
From my personal point of view, if torch could provide a way to “expose” a resource or service upon the RPC module, even RemoteModule could be easily implemented, since it is basically create a module on a remote process, then expose its “__call__()” method as a service on the global scope, #41546 could solve this problem.
Summary:
You can achieve all functions, using current torch APIs, if you don’t mind 20% ~ 30% efficiency loss, and spend a little?(much) time to construct your wheel, if you don’t, you can also use mine . It would be definetly better if torch could just provide these functions, with more optimizations.
And @mrshenli@Kiuk_Chung, please chime in and offer some feedback and precious suggestions on #41546, there are some torchelastic issues I am not very familiar with and need some help
This idea comes from “micro services”. It makes your application logic much more clearer to understand. RFC proposal #41546 also contains an automatic role-based launcher implementation to address this issue.
However, role based design is not compatiable with:
if __name__ == "__main__":
...
tensor.to("worker:0/cuda:1")
# do some computation
tensor.to("worker:1/cuda:0")
because you are manually specifying every destination and location,