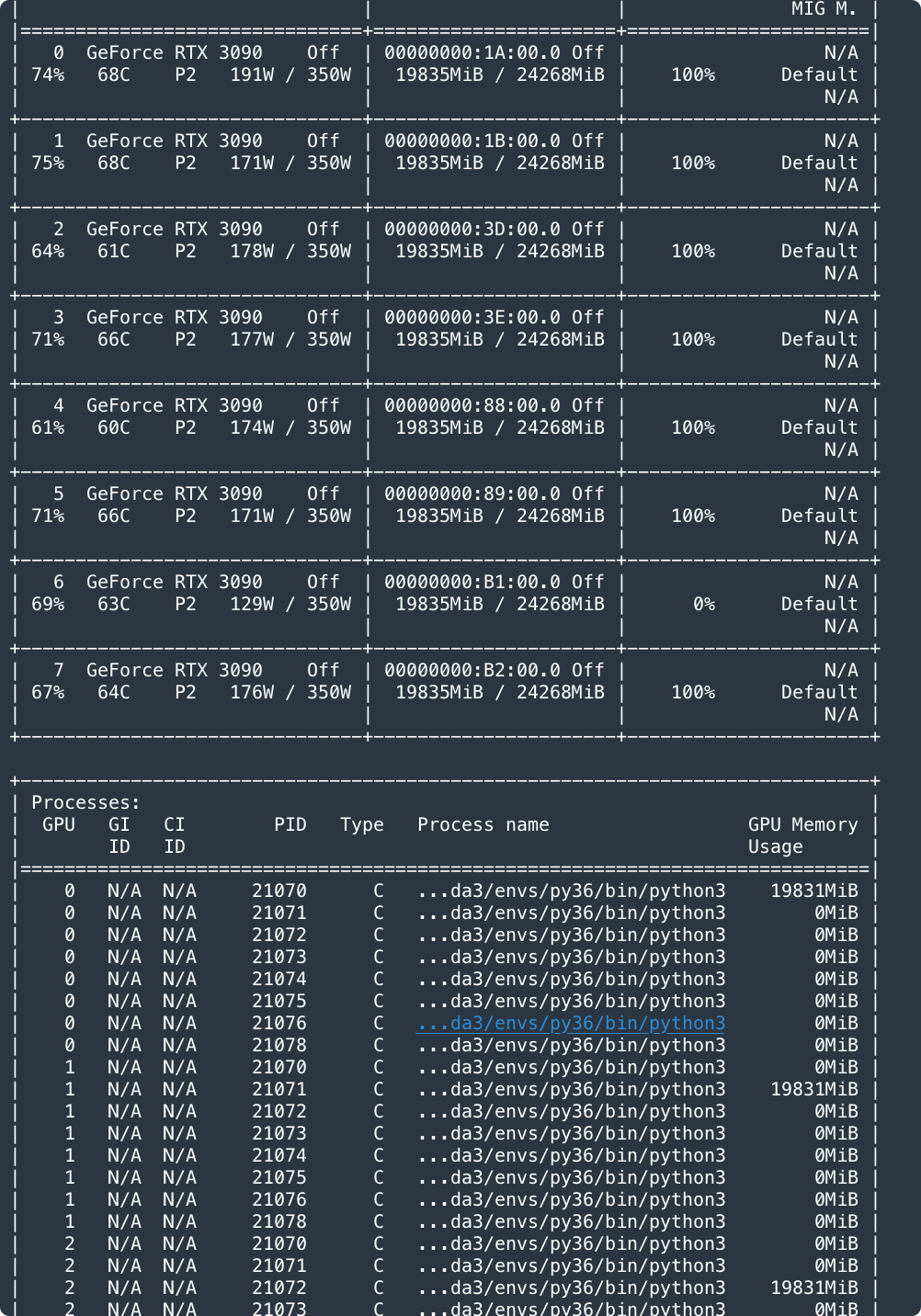
I used DistributedDataParallel and nccl as backend in my code. I ran my code as python3 -m torch.distributed.launch --nproc_per_node=8 train.py. However, Pytorch creates a lot of redundant processes on other GPUs with memory 0 as shown below.
I used 8 * 3090 and Pytorch 1.7. It creates 8 processes on every single GPU.
Looks like each process is using multiple GPUs. Is this expected? If not, can you try setting CUDA_VISIBLE_DEVICES env var properly for each process before creating any CUDA context?