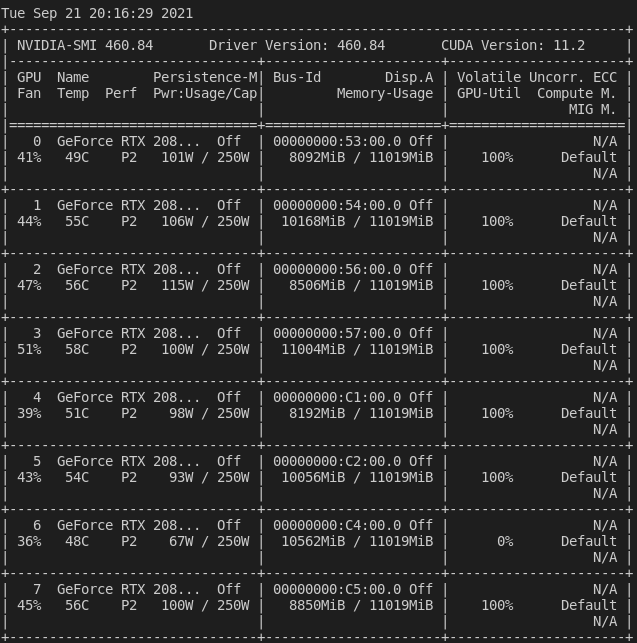
The problem got more serious: several dataloaders got completely stuck, and the others are waiting for them.
I try print some information once the __getitem__ function is called.
def __getitem__(self, idx):
print(f'rank {torch.distributed.get_rank()}, fetch sample {idx}')
# my custom transformations ...
After several iterations I got following information:
rank 4, fetch sample 1469
rank 2, fetch sample 3282
rank 5, fetch sample 2757
rank 1, fetch sample 1355
rank 3, fetch sample 279
rank 0, fetch sample 4107
rank 7, fetch sample 2834
Rank 6 is missing, and the GPU information is as follows.
After sending an interrupt, the traceback is:
File "/root/.pyenv/versions/3.6.8/lib/python3.6/site-packages/mmdet/apis/train.py", line 170, in train_detector
runner.run(data_loaders, cfg.workflow)
File "/root/.pyenv/versions/3.6.8/lib/python3.6/site-packages/mmcv/runner/epoch_based_runner.py", line 127, in run
epoch_runner(data_loaders[i], **kwargs)
File "/root/.pyenv/versions/3.6.8/lib/python3.6/site-packages/mmcv/runner/epoch_based_runner.py", line 47, in train
for i, data_batch in enumerate(self.data_loader):
File "/root/.pyenv/versions/3.6.8/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 521, in __next__
data = self._next_data()
File "/root/.pyenv/versions/3.6.8/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 1186, in _next_data
idx, data = self._get_data()
File "/root/.pyenv/versions/3.6.8/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 1152, in _get_data
success, data = self._try_get_data()
File "/root/.pyenv/versions/3.6.8/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 990, in _try_get_data
data = self._data_queue.get(timeout=timeout)
File "/root/.pyenv/versions/3.6.8/lib/python3.6/multiprocessing/queues.py", line 104, in get
if not self._poll(timeout):
File "/root/.pyenv/versions/3.6.8/lib/python3.6/multiprocessing/connection.py", line 257, in poll
return self._poll(timeout)
File "/root/.pyenv/versions/3.6.8/lib/python3.6/multiprocessing/connection.py", line 414, in _poll
r = wait([self], timeout)
File "/root/.pyenv/versions/3.6.8/lib/python3.6/multiprocessing/connection.py", line 911, in wait
ready = selector.select(timeout)
File "/root/.pyenv/versions/3.6.8/lib/python3.6/selectors.py", line 376, in select
fd_event_list = self._poll.poll(timeout)
KeyboardInterrupt
Anyone has any idea? @wayi @AndreaSottana @ptrblck