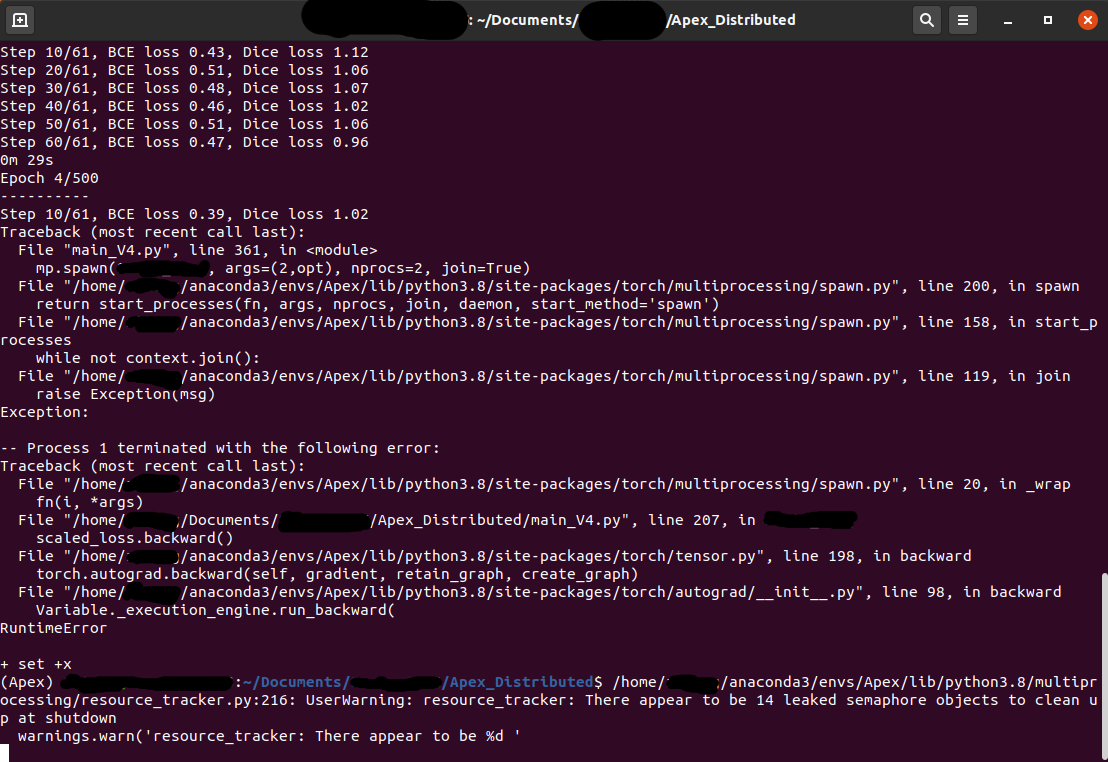
Hi, I am training a UNet on a single machine with 2 GPU. The codes work fine when only using PyTorch’s distributed package (with DistributedDataParallel). However, when training with Apex, I am getting weird errors if I set opt_level=‘O0’, but trainings with opt_level=‘O1’ are always fine. The error always happen on process 1 at scaled_loss.backward(). Any suggestion is appreciated. Thanks.
Error message:
Traceback (most recent call last):
File “main_V4.py”, line 339, in
mp.spawn(YYY_Proj, args=(2,opt), nprocs=2, join=True)
File “/home/ZZZ/anaconda3/envs/Apex/lib/python3.8/site-packages/torch/multiprocessing/spawn.py”, line 200, in spawn
return start_processes(fn, args, nprocs, join, daemon, start_method=‘spawn’)
File “/home/ZZZ/anaconda3/envs/Apex/lib/python3.8/site-packages/torch/multiprocessing/spawn.py”, line 158, in start_processes
while not context.join():
File “/home/ZZZ/anaconda3/envs/Apex/lib/python3.8/site-packages/torch/multiprocessing/spawn.py”, line 119, in join
raise Exception(msg)
Exception:
– Process 1 terminated with the following error:
Traceback (most recent call last):
File “/home/ZZZ/anaconda3/envs/Apex/lib/python3.8/site-packages/torch/multiprocessing/spawn.py”, line 20, in _wrap
fn(i, *args)
File “/home/ZZZ/Documents/YYY_XXX/Apex_Distributed/main_V4.py”, line 191, in YYY_Proj
scaled_loss.backward()
File “/home/ZZZ/anaconda3/envs/Apex/lib/python3.8/site-packages/torch/tensor.py”, line 198, in backward
torch.autograd.backward(self, gradient, retain_graph, create_graph)
File “/home/ZZZ/anaconda3/envs/Apex/lib/python3.8/site-packages/torch/autograd/init.py”, line 98, in backward
Variable._execution_engine.run_backward(
RuntimeError
- set +x
/home/ZZZ/anaconda3/envs/Apex/lib/python3.8/multiprocessing/resource_tracker.py:216: UserWarning: resource_tracker: There appear to be 14 leaked semaphore objects to clean up at shutdown
warnings.warn('resource_tracker: There appear to be %d ’