Hi
I’m training a model on multiple GPUs on a single machine, and I found that the backward call is taking much longer time when distributed training, compared to single GPU training.
A script to reproduce:
import torch.distributed as dist
from argparse import ArgumentParser
import timm
import torch
import os
import time
def main(args):
if "RANK" in os.environ and "WORLD_SIZE" in os.environ:
args.rank = int(os.environ["RANK"])
args.world_size = int(os.environ["WORLD_SIZE"])
args.gpu = int(os.environ["LOCAL_RANK"])
args.distributed = True
rank = args.gpu
torch.cuda.set_device(args.gpu)
args.dist_backend = "nccl"
dist.init_process_group(
backend=args.dist_backend, init_method=args.dist_url, world_size=args.world_size, rank=args.rank
)
dist.barrier()
else:
args.distributed = False
rank = 0
model = timm.create_model('resnet101').cuda()
if args.distributed:
print('distributed')
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[int(os.environ["LOCAL_RANK"])])
else:
print('not distributed')
bs = 16
x = torch.randn(bs, 3, 224, 224).cuda()
label = torch.randint(0, 1000, (bs,)).cuda()
durations = []
for i in range(20):
out = model(x)
loss = torch.nn.functional.cross_entropy(out, label)
t = time.time()
loss.backward()
duration = time.time() - t
print(rank, duration)
durations.append(duration)
print(rank, "avg time:", sum(durations)/len(durations))
if __name__ == "__main__":
parser = ArgumentParser()
parser.add_argument("--world-size", default=1, type=int)
parser.add_argument("--dist-url", default="env://")
args = parser.parse_args()
main(args)
If I run
CUDA_VISIBLE_DEVICES=6,7 torchrun --nproc_per_node=2 main.py
the output looks like:
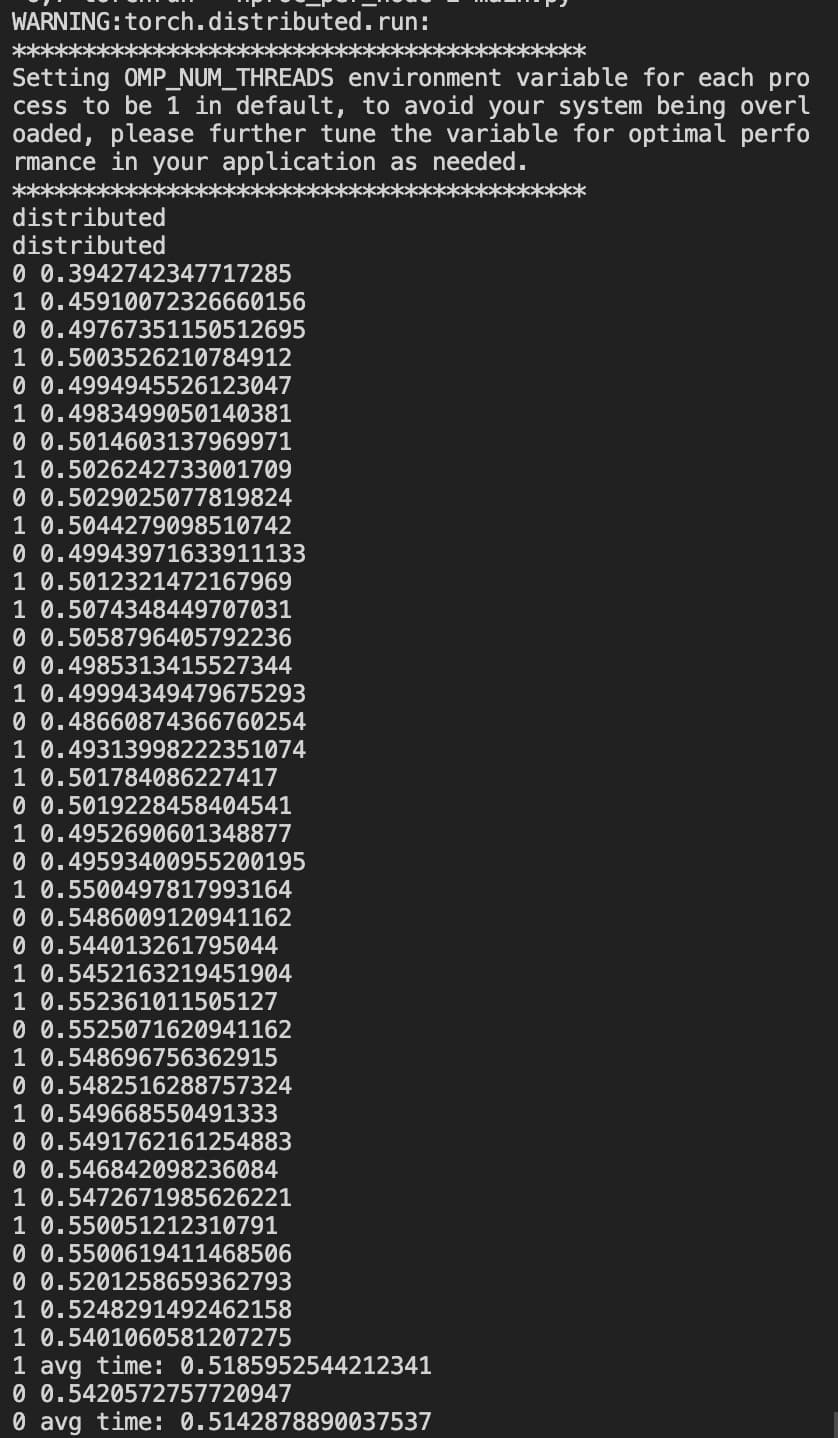
Avg time for backward call is about 0.5s
If I run
python main.py
The output is
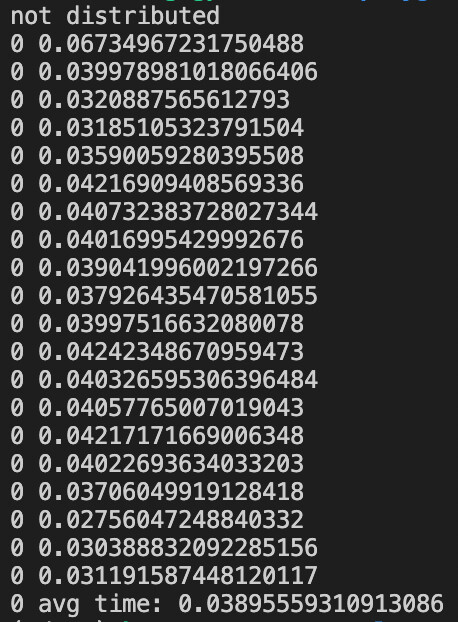
Avg time for backward call is about 0.03s
This behavior is similar to what happened to my main project, where if I use a single GPU it takes about 2 days to train one epoch, but if I use 4 GPUs, it would take about 7 days to train one epoch. And the GPU utilization is always 100% in both cases.
What might be the problem for this slow backward call? Is this behavior in this small example actually expected?