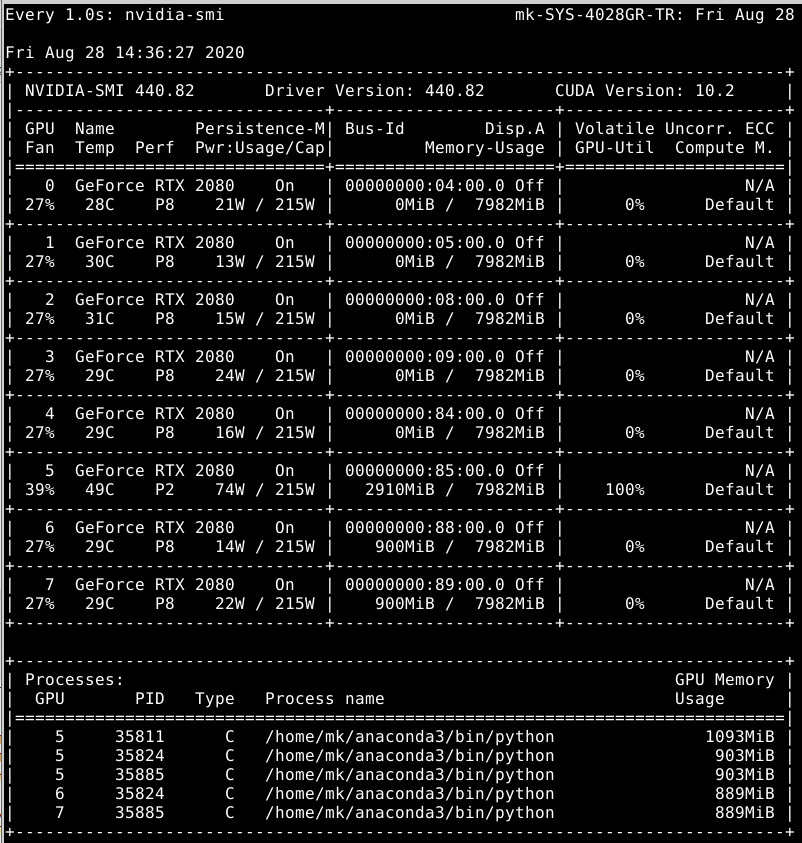
I am trying to apply distributed training in my project, but got a strange problem. It seems all data were loaded to one gpu, please see the figure below.
By the way, I am using pytorch 1.5, Ubuntu 18.04.
I am trying to apply distributed training in my project, but got a strange problem. It seems all data were loaded to one gpu, please see the figure below.
By the way, I am using pytorch 1.5, Ubuntu 18.04.
Looks like all processes create some states on cuda:5. It’s possible that some part of the code is using default device. One option is to use set_device to set the current device before creating any context/data on the device. Another option is to set CUDA_VISIBLE_DEVICES to make sure that each process can only see one device.
BTW, could you please add a “distributed” tag for distributed-training related questions? Developers working on the distributed package actively monitors that tag.
I did set CUDA_VISIBLE_DEVICES in my project, and it seems doesn’t work. And I couldn’t find a way to add tags afterwards.
How did you set CUDA_VISIBLE_DEVICES? Did you set it in the very beginning of every spawned subprocess?
One way to verify is to add the following line right before where init_process_group is called in each subprocess.
print(os.environ['CUDA_VISIBLE_DEVICES'])
Not the very beginning, but before mp.spawn was called. And I did what you say, the result is here (mp.spawn is called in launch.launch). I think the correct result should be one single number at each time, but how to fix it?
Is the intention to let each process see 3 devices? If each process only works on one device, it’s better to let it see only one device, so that it won’t accidentally create states on other devices?
My problem has been fixed. Thanks a lot!
