Hi there,
I’m trying to train my network wrapped with DistributedDataParallel on a single machine with 4 GPUs. It went smoothly until the 43rd epoch. The training process was interrupted by CUDA out of memory error on GPU 2.
Traceback (most recent call last):
File "train_ddp.py", line 247, in <module>
trainer.training(epoch)
File "train_ddp.py", line 171, in training
iter_loss.backward()
File "/scratch/workspace/zsding/anaconda3/lib/python3.6/site-packages/torch/tensor.py", line 107, in backward
torch.autograd.backward(self, gradient, retain_graph, create_graph)
File "/scratch/workspace/zsding/anaconda3/lib/python3.6/site-packages/torch/autograd/__init__.py", line 93, in backward
allow_unreachable=True) # allow_unreachable flag
RuntimeError: CUDA out of memory. Tried to allocate 752.00 MiB (GPU 2; 15.77 GiB total capacity; 10.24 GiB already allocated; 518.25 MiB free; 785.63 MiB cached)
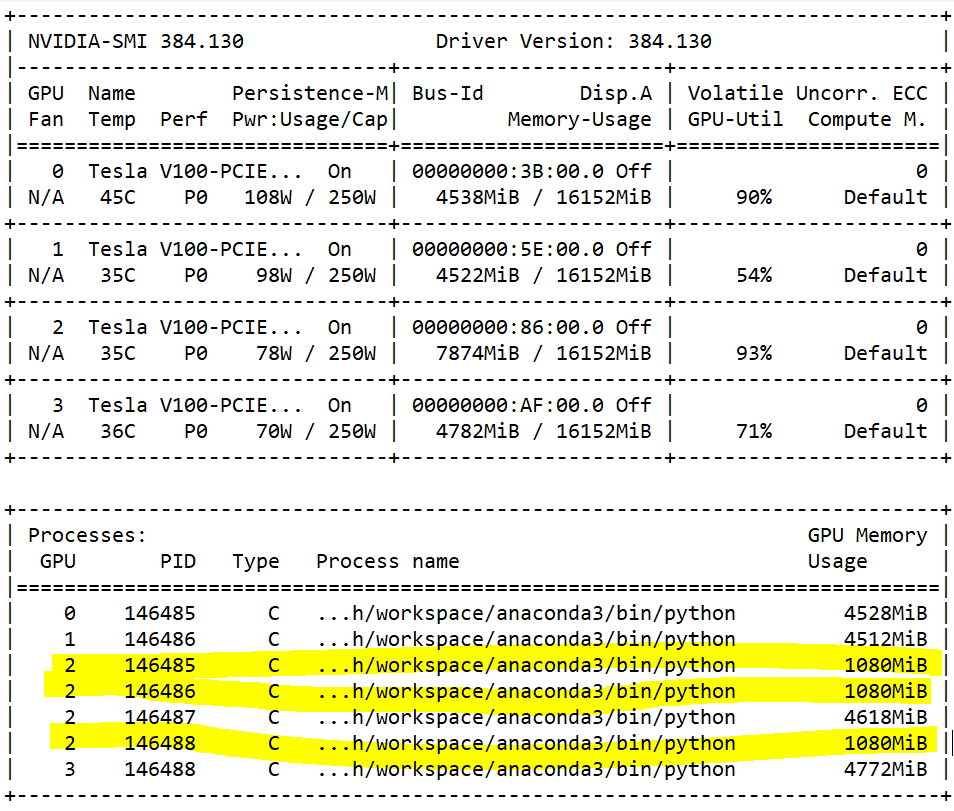
Then I shrank the input size and resumed from my previous weight to try to debug the memory footprint. The chart below shows that there were three extra python threads running and occupying 1080 mib
on GPU 2. And I find that they shared same PID with the threads on other GPUs.
And of course, each GPU has only one thread during the first training epoch. No GPU specific operation (like .to(2)) used in my train script, but I applied SyncBatchNorm on my model (can it be the reason?).
How can I figure out what are those three threads? Could you provide some solutions to solve this problem?
Hi, Is it possible for you to provide a snippet of your code/a way to reproduce the issue that you are seeing? Similar to DataParallel imbalanced memory usage, it could be the case that the outputs of your forward pass are being gathered onto a single GPU (GPU 2 in your case), causing it to OOM.
A bit late here, but I had the exact same issue and the problem was that I was loading a state_dict (saved from the device cuda:0) from four different GPUs, and the resulting effect was that all the GPUs were loading the state_dict in the device cuda:0.
I solved loading the state_dict with: torch.load(<state dict file path>, map_location=current_device)