Past weeks I ran a few more tests, but I still wasn’t able to solve this issue. Here are some training results with different batch sizes and learning rates:
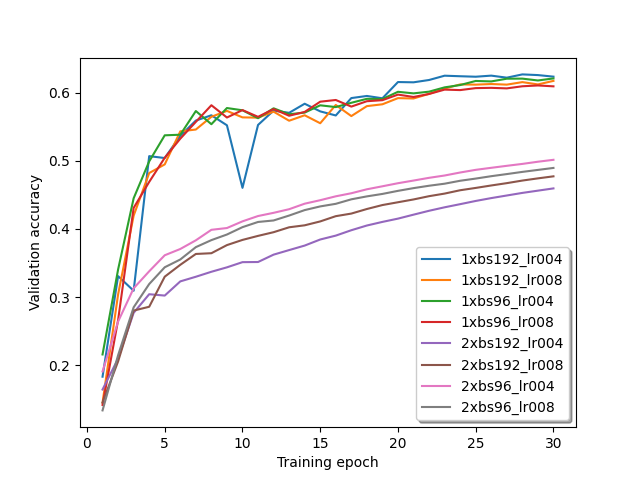
I also tried the ratios of the learning rate and batch size between single GPU and multi GPU training suggested by @wayi . The single GPU curve is still always ahead of the multi GPU curve.
Am I still missing something or is DistributedDataParallel just not working properly? Can please someone confirm its actually possible to achieve a similar progression of the validation accuracy in multi-GPU training using DistributedDataParallel compared to a single GPU training?