Hi,
in our project using multiple gpus for training a resnet50 model with PyTorch and DistributedDataParallel, I encountered a problem. Here is the github-link for our project.
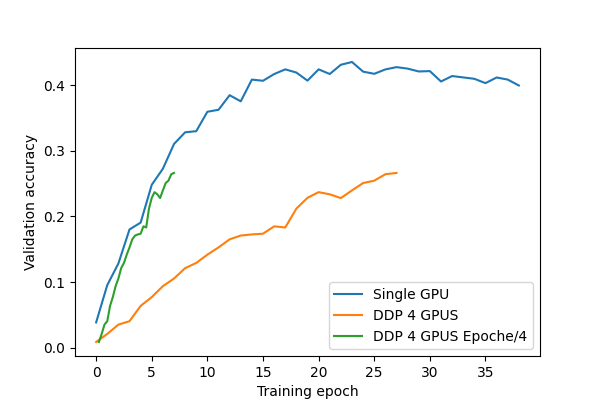
Looking at the comparison of the validation accuracy progress after each epoch between a single GPU and multiple GPUs, it looks like the GPUs don’t share their training results with each other and it’s actually just one GPU training the model.
Here is a comparison between a single Nvidia RTX 3090 and 4 Nvidia RTX 3090 using the same training parameters trained with the imagenet dataset.
If the epoch axes of the 4x3090 graph is divided by the number of gpus (green curve), the graph has a similar shape like the one of the single GPU (blue curve). So basically training with 4 GPUS needs 4 epochs to get the same results like a single GPU achieves in only 1 epoch. Since the dataset is distributed over all GPUS, each GPU only uses 1/4 of the whole dataset, explaining the worse training result for each GPU after each epoch.
Playing around with training parameters like using different batch sizes and learning rates gives me the same result. I have another comparison with different training parameters following in the next post because of the limit of embedded media for new users.
No matter what batch size or learning rate is used, training with a single GPU is always much more efficient then training with multiple GPUS using DistributedDataParallel.
I also ran different tests with smaller datasets and different training parameters with the same effect.
Using DataParallel instead of DistributedDataParallel works as expected: The training of multiple GPUS with a batchsize divided by the number of GPUS gives similar results as the training of a single GPU with the full batchsize.
But since DataParallel is much slower than DistributedDataParallel, I would be very grateful, if someone could give me a hint what I am doing wrong.
Thank you in advance
So basically training with 4 GPUS needs 4 epochs to get the same results like a single GPU achieves in only 1 epoch.
This is not true if you consider the sync among 4 GPUs per epoch. It should be equivalent to running 4 epochs on a single GPU.
Can you confirm if there is any communication between different processes (by printing the gradient values of different ranks after backward)? Gradients of different ranks should be the same after backward.
Additionally, your repo has an arg average_gradients. If you turn on this as a duplicate gradient averaging step, will it achieve the same accuracy as a single GPU?
I checked the gradient values of different ranks after the backward propagation and can confirm they are equal over all ranks. So the communication/sync between the GPUs seems to work. But I still don’t understand why the development of the validation accuracy is still that bad in our case. I wasn’t able to get a training setting where multiple GPUs using DistributedDataParallel gives a benefit over a single GPU. The epochs in a training with 4 GPUs are 4x shorter (because each GPU works with only 1/4 of the dataset) but we need 4x the amount of epochs to get the same result.
The option average_gradients I added as a try to solve this issue. But since the gradients of all ranks are already synced, it has no effect and the gradients remain unchanged.
With DataParallel this issue doesn’t occur. That means training with multiple GPUs using a global batchsize divided by the number of GPUs (to have the same local batchsize) gives similar results as a single GPU with the full batchsize. But since DataParallel is significantly slower then DistributedDataParallel and we are trying to make multi-GPU-training as performant as possible, it would be awesome to solve this with DistributedDataParallel.
having the exact same issue, only monitoring training accuracy/loss. Also, training is slower that DataParallel and even single GPU. Wondering if/how you solved this. On a related note, would really appreciate a pointer to a detailed discussion/documentation of DistributedDataParallel… so far, I’m learning by making mistakes since the tutorials don’t seem to cover it comprehensively (or I haven’t found them yet).
The epochs in a training with 4 GPUs are 4x shorter (because each GPU works with only 1/4 of the dataset) but we need 4x the amount of epochs to get the same result.
With DataParallel this issue doesn’t occur.
Putting these two together, looks like the loss function might play a role here. With DDP, the gradient synchronization only occurs during the backward pass after loss computation, which means that each process/GPU independently computes the loss using its local input split. In contrast, DataParallel does not have this problem, as forward output is first gathered and then the loss is computed over all input data in that iteration. Will this make a difference in your application?
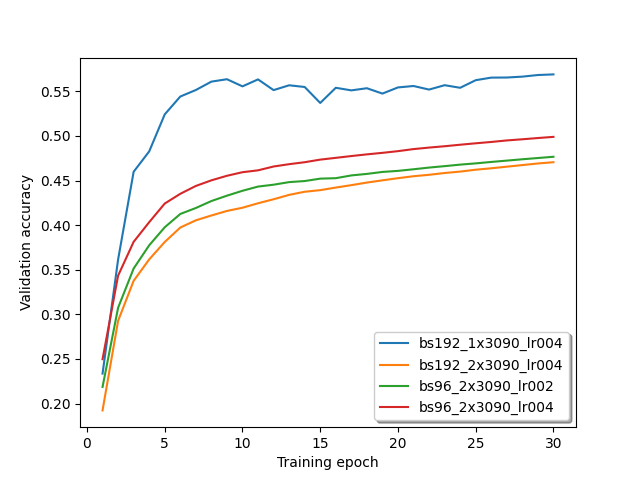
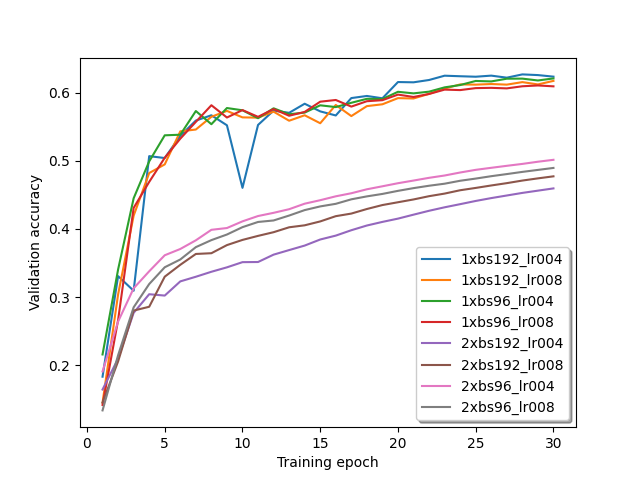
Past weeks I ran a few more tests, but I still wasn’t able to solve this issue. Here are some training results with different batch sizes and learning rates:
I also tried the ratios of the learning rate and batch size between single GPU and multi GPU training suggested by @wayi . The single GPU curve is still always ahead of the multi GPU curve.
Am I still missing something or is DistributedDataParallel just not working properly? Can please someone confirm its actually possible to achieve a similar progression of the validation accuracy in multi-GPU training using DistributedDataParallel compared to a single GPU training?
Hi! I’ve faced the same issue. The solution was to increase learning rate proportional to the increase in the total batch size - as explained in details in this great article.
In particular when I’ve used same learning rate for training on 1 GPU and 4 GPUs - there was no speed up at all. But when I’ve multiplied the learning rate by 4 for the 4 GPUs case - it converged much faster. The speed up was almost 4x - linear to the number of GPUs actually.
I am using DDP for model training, but the validate index not achieve my expect while single GPU can achieve my expect,even the time-consuming is shorter.
A Key question. all plots above are about Validation-Acc, on dev set, what is the result on a big enough test set?
A single-GPU training may be more easisly to get a better Acc result, but multi-GPU will get a more smooth result. The all_reduce will get a “everage performance”. not so sharp, but stable.
And if the training data size is very large, and training input condition is much more complex then a simple classifier, You may see stable converge on DDP, but not on single-card.
I think, whether you should chose single-card or DDP, is decided on many situations, eg. the task your are training, the size of trainging dataset, the complexity of training inputs, and the traning strategy.