Hi, I’m new to DistributedDataParallel(DDP). I have lots of problem with this module…
I tried to run code like below.(from Getting Started with Distributed Data Parallel — PyTorch Tutorials 2.2.0+cu121 documentation)
import os
import tempfile
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
import torch.nn as nn
import torch.optim as optim
from torch.nn.parallel import DistributedDataParallel as DDP
def setup(rank, world_size):
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '12355'
# initialize the process group
dist.init_process_group("gloo", rank=rank, world_size=world_size)
def cleanup():
dist.destroy_process_group()
class ToyModel(nn.Module):
def __init__(self):
super(ToyModel, self).__init__()
self.net1 = nn.Linear(10, 10)
self.relu = nn.ReLU()
self.net2 = nn.Linear(10, 5)
def forward(self, x):
return self.net2(self.relu(self.net1(x)))
def demo_basic(rank, world_size):
print(f"Running basic DDP example on rank {rank}.")
setup(rank, world_size)
# create model and move it to GPU with id rank
for x in range( 1, 10000):
model = ToyModel().to(rank)
ddp_model = DDP(model, device_ids=[rank])
loss_fn = nn.MSELoss()
optimizer = optim.SGD(ddp_model.parameters(), lr=0.001)
optimizer.zero_grad()
outputs = ddp_model(torch.randn(20, 10))
labels = torch.randn(20, 5).to(rank)
loss_fn(outputs, labels).backward()
optimizer.step()
def run_demo(demo_fn, world_size):
mp.spawn(demo_fn,
args=(world_size,),
nprocs=world_size,
join=True)
if __name__ == "__main__":
n_gpus = torch.cuda.device_count()
if n_gpus < 4:
print(f"Requires at least 4 GPUs to run, but got {n_gpus}.")
else:
run_demo(demo_basic, 4)
run with
python3 new.py
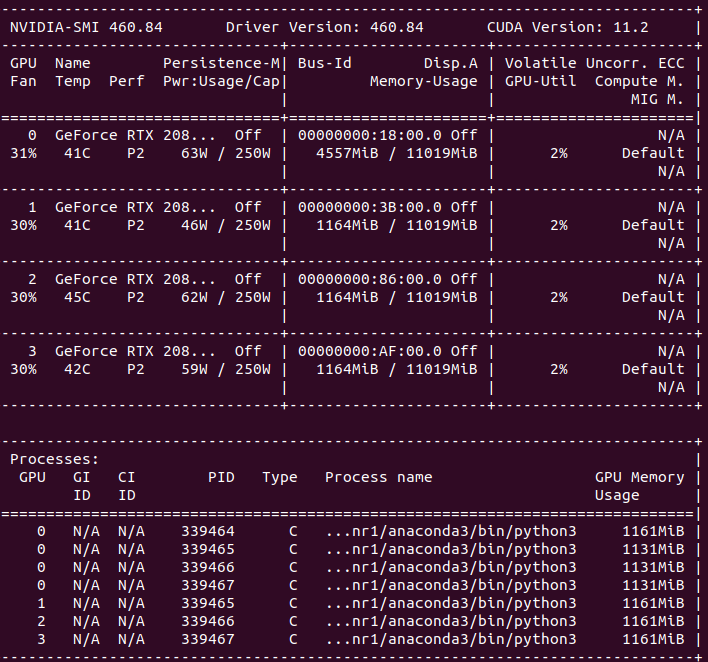
However, when I monitor ‘nvidia-smi’. There are 4 process in GPU 0. Why not one process for each GPU device?