Hello everyone,
I am currently implementing my research idea in the following picture:
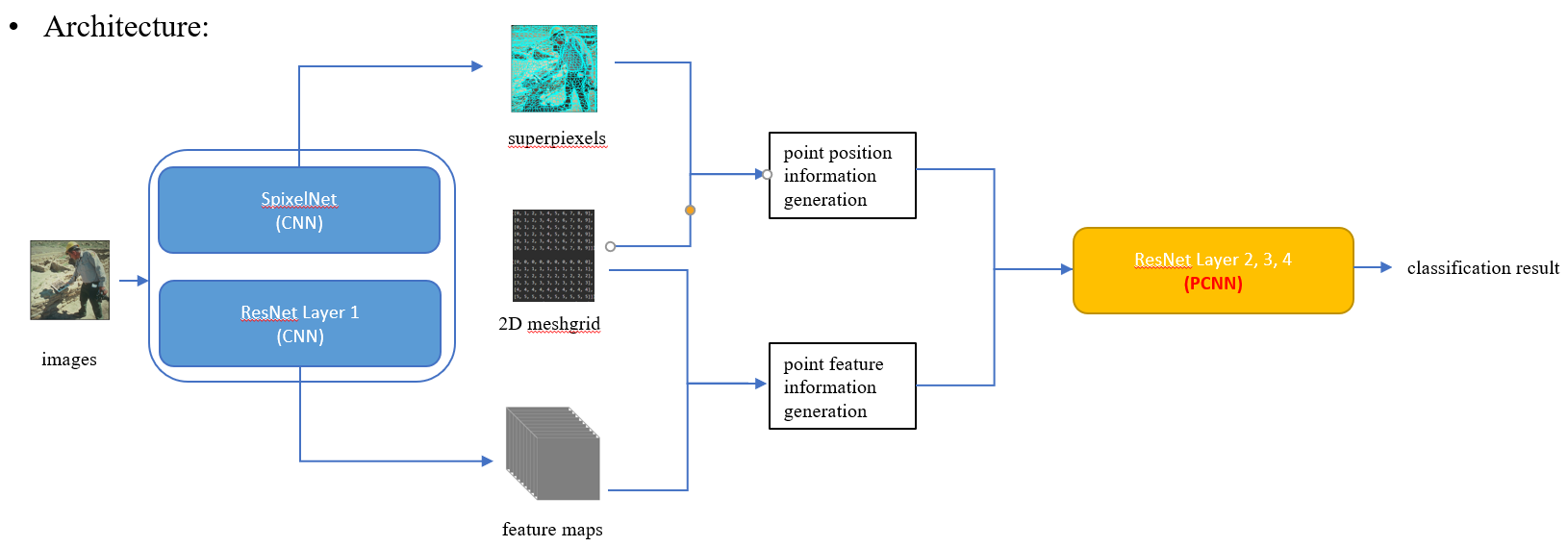
Based on the information on asynchronous execution, I know I don’t need to worry too much about the “forward” function. However, is it that possible to use " torch.cuda.stream" could be faster than without using it? I hope someone can answer my question. Thank you very much.
H
To clarify my question, I display two sample implementations (incomplete code to clarifying my question).
- without " torch.cuda.stream"
class PointConvResNet(nn.Module):
def __init__(self):
self.spixelnet = SpixelNet()
self.layer1 = ResNet().layer1
self.layer2 = self._make_layer(block, 128, layers[1])
self.layer3 = self._make_layer(block, 256, layers[2])
self.layer4 = self._make_layer(block, 512, layers[3])
self.avgpool = nn.AdaptiveAvgPool1d((1,))
self.fc = nn.Linear(512 * block.expansion, num_classes)
def forward(self, images):
superpixels = self.spixelnet(images)
x = self.conv1(images)
x = self.bn1(x)
x = self.relu(x)
x = self.layer1(x)
xy = convert_xy(superpixels, self.imsize[0], self.imsize[1])
points = convert_points(x, superpixels, self.imsize[0], self.imsize[1])
xy, points = self._forward_impl(xy, points, self.wsize[0], self.layer2)
xy, points = self._forward_impl(xy, points, self.wsize[1], self.layer3)
xy, points = self._forward_impl(xy, points, self.wsize[2], self.layer4)
x = self.avgpool(points)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
2 use " torch.cuda.stream"
class PointConvResNet(nn.Module):
def __init__(self):
self.spixelnet = SpixelNet()
self.layer1 = ResNet().layer1
self.layer2 = self._make_layer(block, 128, layers[1])
self.layer3 = self._make_layer(block, 256, layers[2])
self.layer4 = self._make_layer(block, 512, layers[3])
self.avgpool = nn.AdaptiveAvgPool1d((1,))
self.fc = nn.Linear(512 * block.expansion, num_classes)
self.stream1 = torch.cuda.Stream()
self.stream2 = torch.cuda.Stream()
def forward(self, images):
with torch.cuda.stream(stream1):
superpixels = self.spixelnet(images)
with torch.cuda.stream(stream2):
x = self.conv1(images)
x = self.bn1(x)
x = self.relu(x)
x = self.layer1(x)
xy = convert_xy(superpixels, self.imsize[0], self.imsize[1])
points = convert_points(x, superpixels, self.imsize[0], self.imsize[1])
xy, points = self._forward_impl(xy, points, self.wsize[0], self.layer2)
xy, points = self._forward_impl(xy, points, self.wsize[1], self.layer3)
xy, points = self._forward_impl(xy, points, self.wsize[2], self.layer4)
x = self.avgpool(points)
x = torch.flatten(x, 1)
x = self.fc(x)
return x