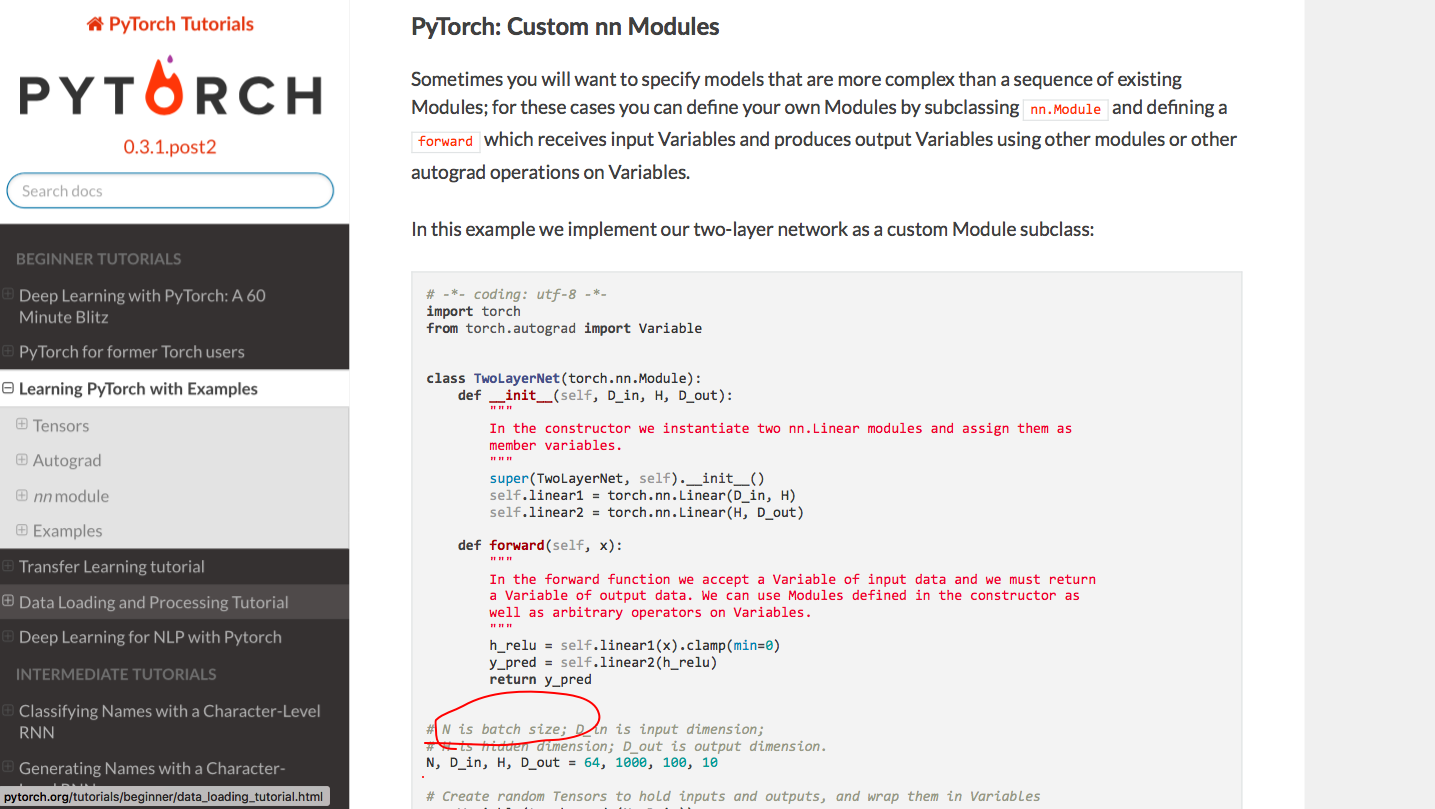
we need to consider the batch_size when using the Linear layer. Then if I define own module ,do i need to consider the batch_size, e.g if the original input is a input_feature Tensor, if we consider the batch_size, then the input will be batch_size*input_feature Tensor
You don’t need to consider the batch size when initializing the Modules. The Linear layer for example takes in_features as an argument, which would be dimension 1 for x = torch.randn(10, 20).
However, when you need another view on the Tensor, e.g when you need to flatten the Tensor coming from a Conv2d, you most likely want to keep the batch size and flat all remaining dimensions.
You would do it in the forward method:
x = self.conv(x)
x = x.view(x.size(0), -1) #keep batch size
x = self.fc(x)
The implementation of models “from any paper” depends on the definition of the authors. While built-in layers (and other standard layers) do not hard-code the batch size, it’s impossible to speak for all authors.