I am trying to trace nvidia’s tacotron 2 model and interface with it via. the C++ frontend.
Running the traced function via. the Python frontend works just fine, and reports results as expected.
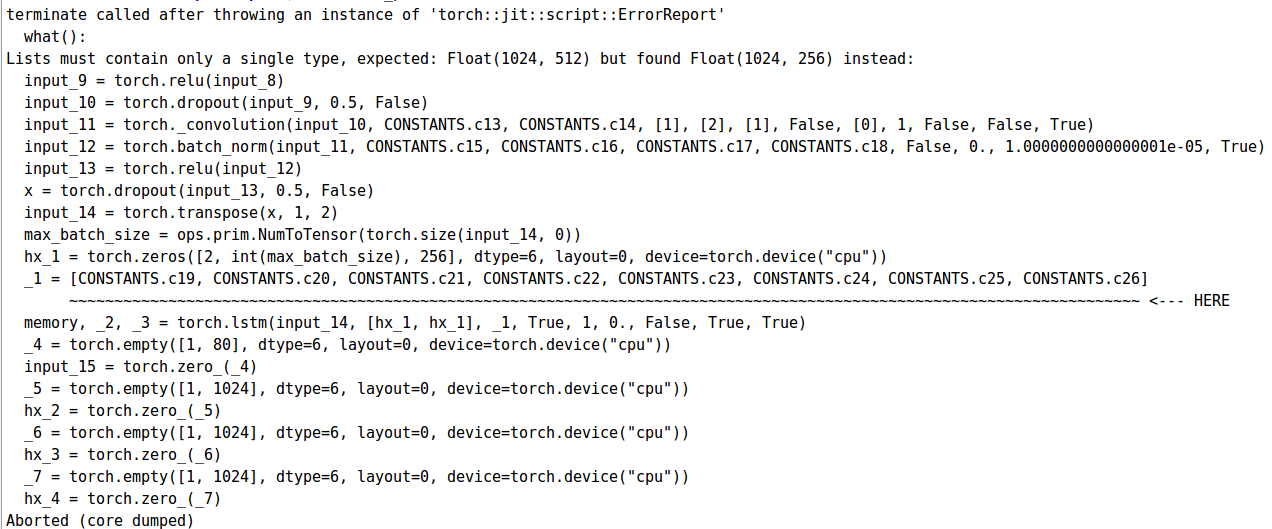
Through the C++ frontend however, it complains of a list of weights being fed into tacotron’s decoder LSTM not being of equal size (as each weight parameter is of different size/type).
The code used to trace and export out the model is as follows (nvidia’s implementation is linked here: GitHub - NVIDIA/tacotron2: Tacotron 2 - PyTorch implementation with faster-than-realtime inference):
import numpy as np
import torch
from hparams import create_hparams
from text import text_to_sequence
from train import load_model
hparams = create_hparams()
hparams.sampling_rate = 22050
tacotron = load_model(hparams)
tacotron.load_state_dict(torch.load("tacotron2_statedict.pt", map_location='cpu')['state_dict'])
tacotron.eval()
print(tacotron)
text = "This is some random text."
sequence = np.array(text_to_sequence(text, ['english_cleaners']))[None, :]
sequence = torch.autograd.Variable(torch.from_numpy(sequence)).long()
traced_tacotron = torch.jit.trace(tacotron.inference, sequence, optimize=False, check_trace=False)
traced_tacotron.save("tacotronzzz.pt")
print(tacotron.inference(sequence))
Here is the C++ frontend code:
#include <iostream>
#include <torch/script.h>
#include <torch/torch.h>
using namespace std;
int main() {
shared_ptr<torch::jit::script::Module> tacotron = torch::jit::load("tacotronzzz.pt");
assert(tacotron != nullptr);
return 0;
}
If it helps, I can also provide a download to tacotronzzz.pt.
Any help is much appreciated; if this is actually a bug, I’m happy to dig into the internals of libtorch and see if this could be fixed in any way.