I just feel a bit confused about whitening, like PCA or similar techniques.
Common approach is to substract mean and divide std on dataset(i.e. mean is dataset mean, std is dataset std)
However, I feel we should do this on batch basis. because we use minibatch to feed into NN and each batch we cannot garentee the batch_mean and batch_std is the same as dataset_mean and dataset_std.
but i did not see anyone doing this on batch basis…
is there something wrong with my understanding? or i miss something?
Thanks for the explaination.
Then my confusion is why we apply standard score on dataset basis? is there any specific reason? Because the first idea come to my mind is to perform everything on batch. My thinking is we only feed in mini-batch to NN, thus we should perform everything on batch-basis…and this is actually how human learns right? we don’t need to know what is the real distribution of the data/datasest, we just try to learn based on samples we have on hand…
Really thanks if you can give me some hints.
I think the main reason is, that you don’t necessarily have batches during testing, which might create bad estimates of the mean and std.
You estimate the statistics of your dataset using the trainset and try to make sure the validation and test data is sampled from the same distribution.
The same would apply e.g. if you use batch norm layers with a batch size of 1.
The running estimates will be noisy and thus the validation and test error might be large.
Relying on a specific batch size seems like a bad idea in the general use case.
Thanks for your explaination, I think it’s quite valid and make sense.
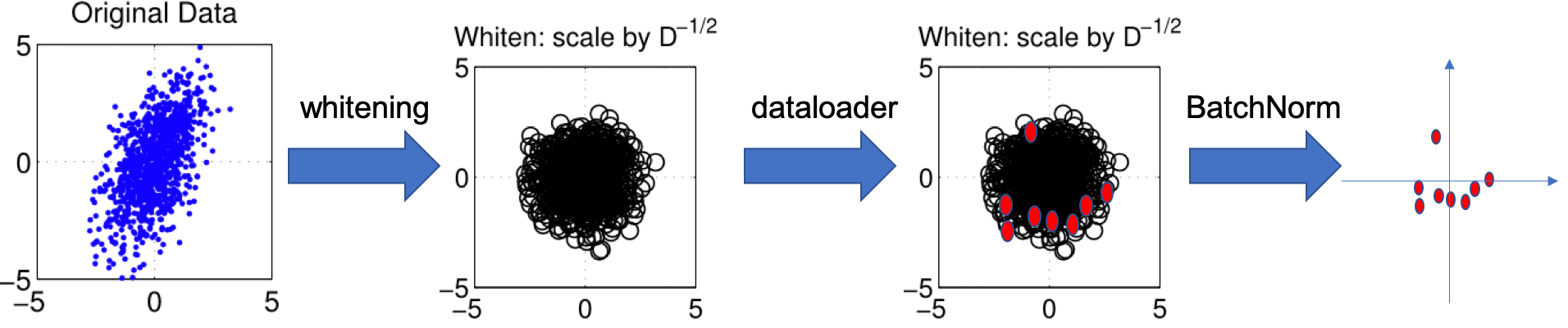
So currently, we have a dataset, and we perform whitening/normalization, then we apply dataloader to generate minibatch, the minibatch maynot follow the dataset distribution right, i.e. mean for minibatch maynot be exactly 0(like the red dots shown in graph)? so that is why we also apply batchnrom to make sure the batch is 0-centered:
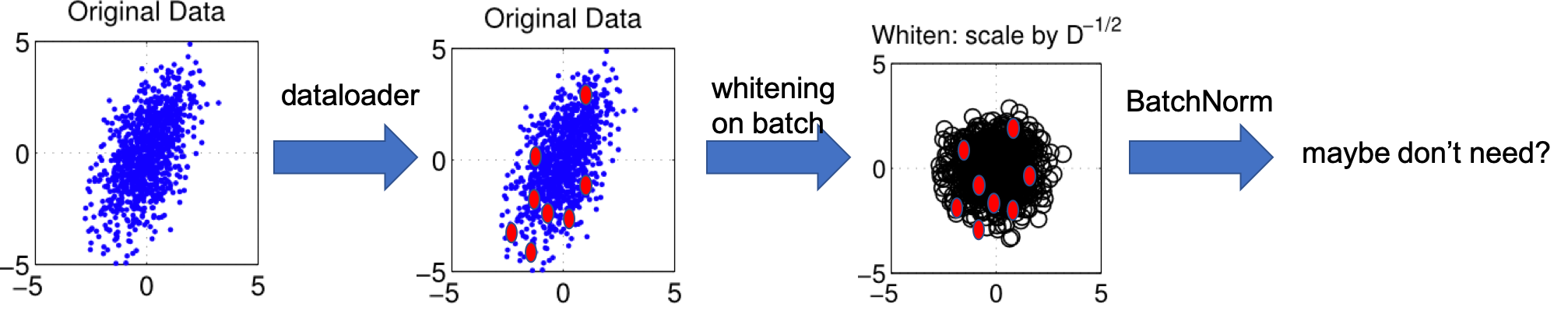
I dont really care the distribution of the dataset, I just directly use them to generate minibatch(red dots), but for every minibatch i do whitening(we calculate the matrix every batch) so i make sure every minibatch is 0-centered, and then maybe I don’t need BatchNorm layers??
and also this approach should not have any problem during testing, because the distribution of test is not important as we whitening on batch
This is something which I feel the main stream approach is different from mine… and I get confused about it…I want to know where I miss something…
actually I am also think about this…so based on current approach(i.e. whitening on dataset basis), how the batch_norm is working if we set Batch_size = 1 in both training and testing? the image(dot) will also be in center right?
During training the batch norm layers will update their running estimates of the mean and std and just apply these estimates during validation and testing.
The momentum term defines the update step of the running estimates using the current batch statistics.
We could see some issues (bad testing accuracy while training looked good), when these estimates are off due to e.g. different data domains for the datasets, and might need to resample/shuffle the data or change the momentum term.
That being said, I don’t want to say that your approach is invalid in any sense.
If you have valid assumptions, how you would like to apply the whitening during training and testing, I would recommend to run some tests and see, how it compares to e.g. standardization and batch norm.