Do we need to define a fixed sentence length when we’re using padding-packing for RNNs? I just developed a small RNN for text classification and realized (after successfully training+testing) that I haven’t specified a sentence length for the number of input neurons to the RNN. Pytorch did not give any errors.
Am I doing something wrong here? Don’t we have to specify a sentence length in order to define the input length for the RNN?
Please have a look at the following snippets of code I used. Input to the dataloader is a list of variable sized tensors. Eg. [[1, 2, 3], [4, 5]]
class SampleData(Dataset):
def __init__(self, X_data, y_data):
self.X_data = X_data
self.y_data = y_data
def __getitem__(self, index):
return self.X_data[index], self.y_data[index]
def __len__ (self):
return len(self.X_data)
sample_data = SampleData(X_train, y_train)
sample_loader = DataLoader(sample_data, batch_size=BATCH_SIZE, collate_fn=lambda x:x)
# X_batch
# [[421, 287, 2480, 1961], [399, 2269, 891, 2355, 353, 406, 1310]]
# y_batch
# [1, 1]
BATCH_SIZE = 2
EMBEDDING_SIZE = 5
VOCAB_SIZE = len(word2idx)
TARGET_SIZE = len(tag2idx)
HIDDEN_SIZE_SAMPLE = 3
STACKED_LAYERS = 4
class ModelGRU(nn.Module):
def __init__(self, embedding_size, vocab_size, hidden_size, target_size, stacked_layers):
super(ModelGRU, self).__init__()
self.word_embeddings = nn.Embedding(num_embeddings = vocab_size, embedding_dim = embedding_size)
self.gru = nn.GRU(input_size = embedding_size, hidden_size = hidden_size, batch_first = True, num_layers=stacked_layers)
self.linear = nn.Linear(in_features = hidden_size, out_features=1)
def forward(self, x_batch):
len_list = list(map(len, x_batch))
padded_batch = pad_sequence(x_batch, batch_first=True)
embeds = self.word_embeddings(padded_batch)
pack_embeds = pack_padded_sequence(embeds, lengths=len_list, batch_first=True, enforce_sorted=False)
rnn_out, rnn_hidden = self.gru(pack_embeds)
linear_out = self.linear(rnn_hidden)
y_out = torch.sigmoid(linear_out)
y_out = y_out[-1]
return y_out
gru_model = ModelGRUSample(embedding_size=EMBEDDING_SIZE, vocab_size=len(word2idx), hidden_size=HIDDEN_SIZE, target_size=len(tag2idx), stacked_layers=STACKED_LAYERS)
# ModelGRUSample(
# (word_embeddings): Embedding(2728, 5)
# (gru): GRU(5, 3, num_layers=4, batch_first=True)
# (linear): Linear(in_features=3, out_features=1, bias=True)
# )
Everything run perfectly fine. But have a look at the following picture. A sentence with different number of words will lead to having different number of neurons as input to the RNN. But by using padding-packing, I have apparently bypassed that step somehow.
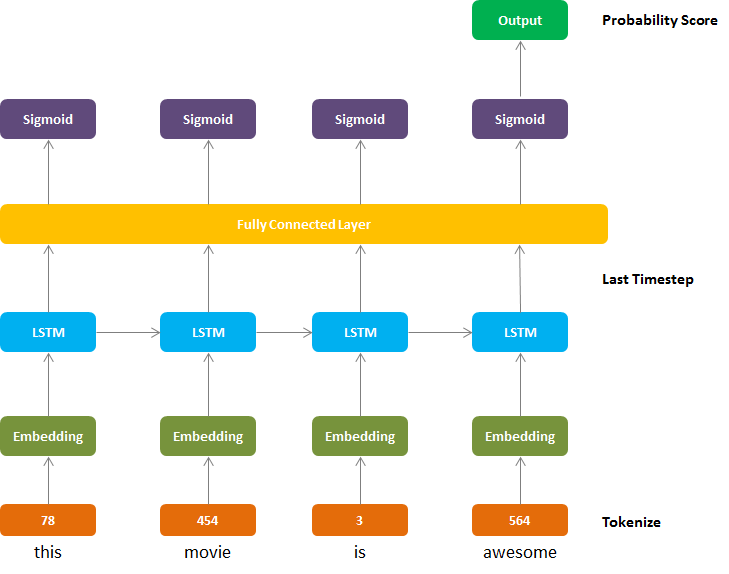
Please tell me what I’m doing wrong. I can’t seem to figure it out.