Hi Cyber!
This is not overfitting (by my definition) and the general structure of
your results does not surprise me.
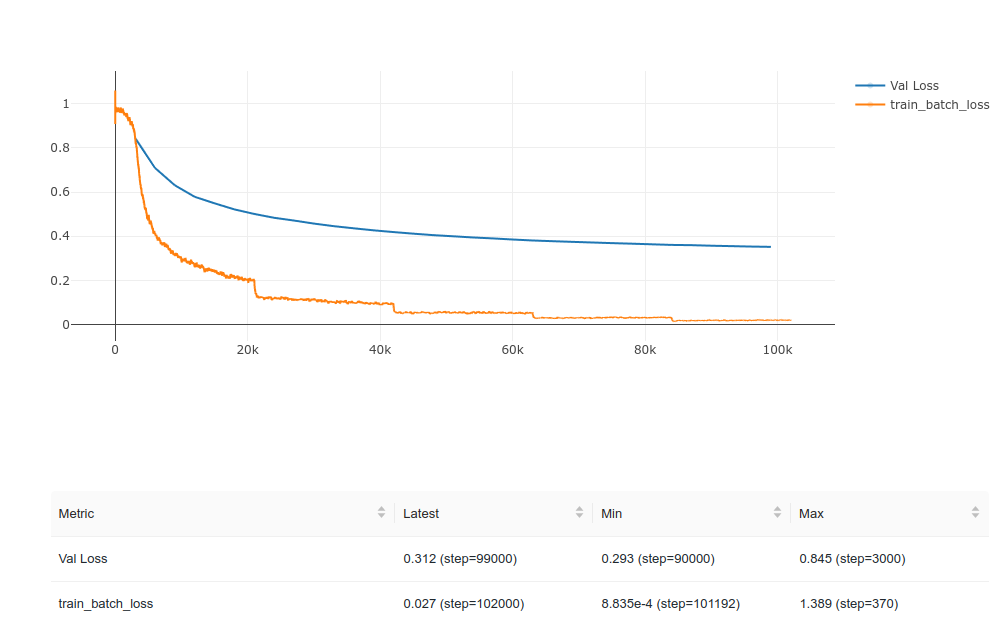
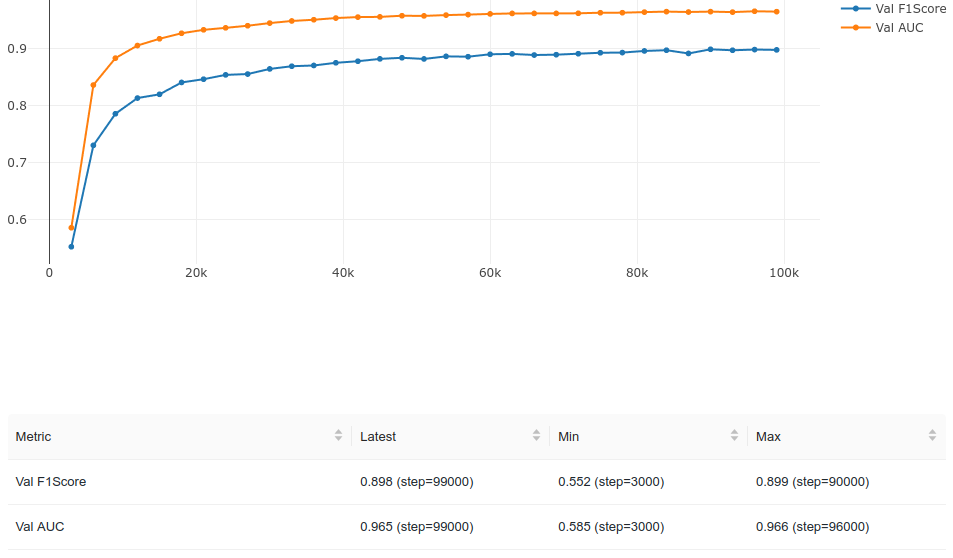
Your validation loss continues to decrease (albeit slowly) and your
validation performance metrics continue to increase. So (as long as
your are happy investing in further training time) keep training to get
a better model.
The gap between your training loss and validation loss is quite typical
of realistic models.
Here’s, crudely, what’s going on:
Your training set encodes two kinds of information: information about
the real problem you’re trying to solve (say cats vs. dogs), e.g., these
cats have intelligent expressions on their faces and these dogs are
scratching fleas; and “random” information specific to your training set,
e.g., this cat picture has a chessboard in the background and this dog
picture has a cluster of dark pixels in the upper right corner.
When you train on your training set, your model learns whatever it
can to get the right answer: both “looks smart,” cat, “fleas,” dog; and
“chessboard,” cat, “dark pixels,” dog help your model make good
predictions on your training set. But only the first two “features” help
your model make good predictions on your validation set. Since your
model makes use of both kinds of information with the training set,
it does a better job – lower loss – on the training set than on the
validation where is can only make use of the first kind of information.
How does overfitting happen? It’s when the model trains its parameters
to focus on “chessboard” vs. “pixels” at the expense of “smart” vs. “fleas.”
It gets better and better and better at the “random,” training-set-specific
information – so the training loss goes down, but it makes increasingly
little use of the “real” information, so the validation loss goes up. The
more you train, the worse your model becomes (expect for the artificial
case of the training set).
So: validation loss keeps going down – keep training (if you care); validation
loss starts going up (systematically – not just little fluctuations) – stop
training because you’re making your model worse.
I don’t know – but it might be interesting and fun to try to figure it out.
The short answer is no – your validation metrics look fine, so your model
is working.
But something is going on. It might be innocuous, but it could be a real
issue that is perhaps making your training less efficient. If it were me, I
would try to track down the cause of the training-loss drops, but I wouldn’t
knock myself about it.
I don’t know how an inner-product layer works, so no idea why. However,
given that you can use your validation set to see how well your model is
actually doing, I would use whatever version of your model ends up
giving you better performance on your validation set after training. If the
training has these unexpected drops in it, so be it (but I’d still spend at
least a little time trying to track down the cause).
Best.
K. Frank