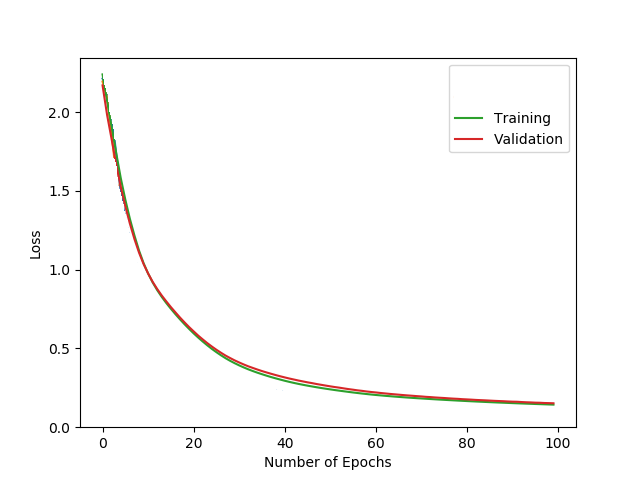
I am using F.log_softmax+nn.NLLLoss and after about 150 epochs both my training and validation are flat around nearly 0
Normally with cross entropy i’d expect the validation curve to go back up (over-fitting) but that is not happening here.
If i understand this set up correctly, the higher the correct prediction confidence is, the closer to 0 it gets?
Does this mean reaching zero is ideal?
Does the fact that my model is trending close to zero mean I should stop training?
How do I explain the validation curve not going back up (away from zero)
Data set is:
9 classes, balanced representation, ~49,000 samples
I did look before I posted, couldn’t find the answer
Your model is perfectly fitting the distribution in the training and validation set.
I don’t want to be pessimistic, but I think something might be wrong.
Could you check the distribution of your labels?
Could it be that your DataLoader is somehow returning the same labels over and over again?
I will post some code later, but in general this is what happens…
If i let this go for longer both training and validation would will stagnate, training at maybe 0.05 and validation at 0.08
Once they hit those numbers (5 and 8) they never improve or get worse.
My concern is that the validation loss never shoots back up
It might be Adam is reducing the per-parameter estimates so that your training stagnate and the val loss doesn’t blow up. You could try a different optimizer like SGD and try it again.
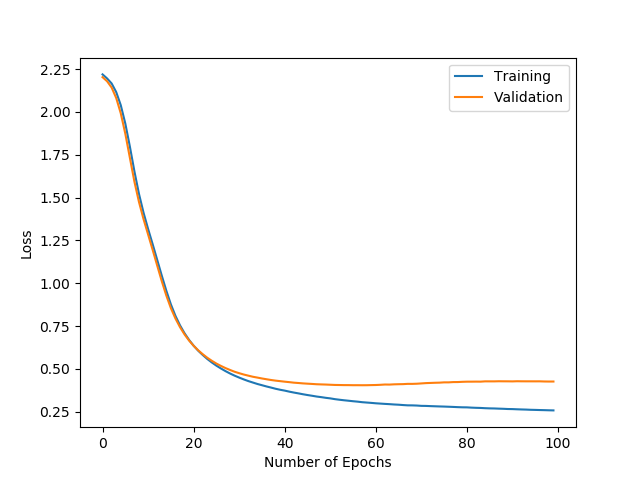
I changed the beta values in Adam and was able to get this
validation does continue to increase passed 100 epochs albeit slowly… training continues to drop slowly
I think also the model might be extremely sensitive to learning rate… this is 3e-5
lowering it starts the causes stranger behavior such as starting losses around 0.5/0.49
I attempted cyclical learning rate but it increases the execution time by hours
To get back to the original question: F.log_softmax + nn.NLLLoss work exactly as raw logits + nn.CrossEntropyLoss.
I think this issue is now more of a general nature.
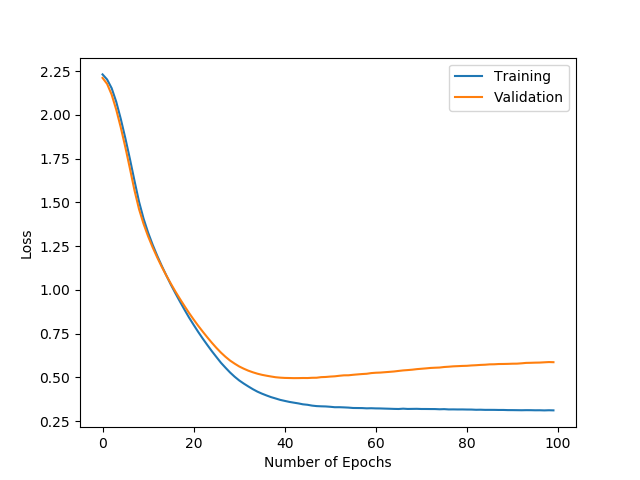
The validation loss might increase after a while. Sometimes your model just gets stuck and both losses stay the same for a (long) while.
I like to check for code or model bugs by using a small part of my training data and try to overfit my model on it, so that it reaches approx. 0 loss.
If that’s not possible with the current code, I will be looking for bugs or change the model architecture.