Hi, I wanted to imitate training with a large batch size using gradient accumulation approach as per this article, due to a lack of GPU memory for a larger batch. A snippet of the code is below:
model.zero_grad() # Reset gradients tensors
for i, (inputs, labels) in enumerate(training_set):
predictions = model(inputs) # Forward pass
loss = loss_function(predictions, labels) # Compute loss function
loss = loss / accumulation_steps # Normalize our loss (if averaged)
loss.backward() # Backward pass
if (i+1) % accumulation_steps == 0: # Wait for several backward steps
optimizer.step() # Now we can do an optimizer step
model.zero_grad() # Reset gradients tensors
if (i+1) % evaluation_steps == 0: # Evaluate the model when we...
evaluate_model() # ...have no gradients accumulated
For some reason, I find that the results of training vary for different values of gradient_accumulation_steps. I also see that others also report different results for different values of gradient_accumulation_steps (for example, this issue is from the project I was trying to replicate).
I was wondering if the number of steps can indeed in any way influence the performance of the model (for a fixed batch size)? My understanding was that this parameter should only has effect on the speed of training, but not the results, as long as the batch size is the same.
Your gradient accumulation approach might change the model performance, if you are using batch-size-dependent layers such as batchnorm layers.
Batchnorm layers will use the current batch statistic to update the running stats. The smaller the batch size the more noise these stats updates will have. You could try to counter this effect by changing the momentum of these layers.
Let me know, if that might be the case or if you are not using batchnorm layers.
Hi, @ptrblck. Yes, this seems to be the probable reason, thank you! I use Roberta as an encoder, so there are some BatchNorm modules in the encoder, but, as far as I can see, there are no batch-size dependent modules in the rest of the model (by the way, I’m curious now, if there any other popular batch-size dependent modules like batch norm).
But I didn’t quite understand, how momentum can help here? Because the momentum term is used for accelerating gradient using gradients from previous batches, but in the scope of several accumulation steps that we have in one batch it doesn’t influence on gradient computation in any way.
Normalization layers might be batch-dependent and of course some custom layers.
I’m not sure if there are any other “core layers”. I guess RNN training would also be different, if you pass the samples sequentially or in a batched way, but this doesn’t seem to be your use case.
Sorry, I meant the batchnorm momentum, which is used to update the running stats.
If your current batch statistics are noisy, you might change the momentum to decrease the current updates.
Hi,
I’m also very curious about this question and I do some experiments.
Set-ups:
RTX3090, Ubuntu 20.04, Nvidia Driver 460.32.03, Cuda 11.1
PyTorch 1.7.1, transformers 4.3.2 (huggingface)
Model: Roberta-large (RobertaForMultipleChoice)
Goal: real batch size (16) = effective batch size (bs_gpu=8, gradient accumulation steps=2)?
Fix all random seeds and all hyperparameters
To my knowledge, the Roberta model uses LayerNorm instead of BatchNorm,
which does not have running statistics.
However, to make sure everything is all right,
I used model.eval() even in training and set the weight and bias in each LayerNorm layer to requires_grad=False. I also disabled gradient norm clipping.
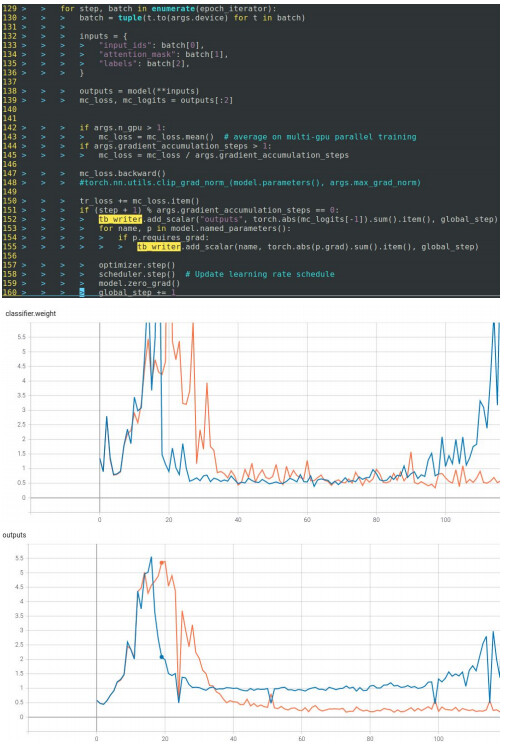
==============================================================================
Results:
Orange line: real batch size; Blue line: effective batch size (using gradient_accumulation)
I only show the plot before the 1st epoch ends in case that the last batch matters
The x-axis is the #global steps (= effective steps)
Fig1: torch.abs(classifier.weight.grad).sum()
Fig2: torch.abs(output).sum() given the same input
There might have some bugs in my code,
if not, my observation is that effective batch size != real batch size,
and the difference becomes very significant after a few steps.
Could it be gradient_accumulation causes some numerical issues and leads to error propagation?
BTW I make sure the plots are the same given the same run using real_batch_size (my code is reproducible)
I wonder if my experiments and suggestion are right?
Thanks
Have you found a solution to this? In my case I experimented with batch size of 8 and gradient acc. steps of 8 vs batch size of 4 and gradient acc. steps of 16 for an effective batch size of 64…
The first converges correctly, the second starts are an even lower loss for the first few steps of training and then explodes…