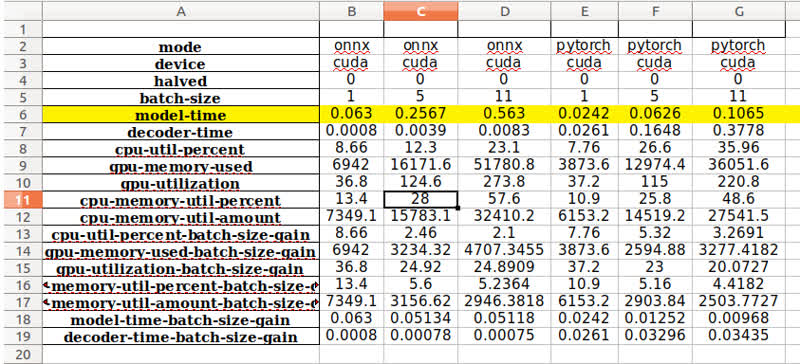
So I have been using Hugginface wave2vecCTC for speech recognition. I want to do as much optimization as possible. One way I have found during my searches was to turn the model into ONNX. So I wrote a Python log script to keep track of GPU, CPU, and runtime duration, with different settings ( Half options-float16-, CPU or GPU, and different batch sizes). Oddly, the Pytorch model outperforms ONNX one. So my question is, is this normal, I thought ONNX is much more efficient when it comes to optimization and inference time. Here is the code I have been using for benchmarking( If you think I am assessing the performance wrong or something is wrong with my code please let me know) :
# from onnxconverter_common import auto_mixed_precision
import os
import onnxruntime
import torch
import psutil
import time
import threading
import pandas as pd
import librosa
import numpy as np
import matplotlib.pyplot as plt
from onnxconverter_common import float16
import onnx
import GPUtil
import argparse
import subprocess
def get_gpu_stats():
command = "nvidia-smi --query-gpu=utilization.gpu,memory.used,memory.total --format=csv,nounits,noheader"#
result = subprocess.run(command, stdout=subprocess.PIPE, shell=True, text=True)
output_lines = result.stdout.strip().split('\n')
gpu_stats = []
for line in output_lines:
values = line.split(',')
utilization = float(values[0])
memory_used = int(values[1])
memory_total = int(values[2])
# return output_lines[0].split(',')
return [utilization , memory_used, memory_total]
def load_and_prepare_model_inputs (model_path, inputs_, export_onnx, halved, device):
# Load the model from ONNX if it exists; otherwise, export and load it
model = Wav2Vec2ForCTC.from_pretrained(model_path )
temp = "halved" if halved else ""
ONNX_Half_Dir = os.path.join("ONNX-Models", f"model" + temp + ".onnx")
ONNXmodelDir = os.path.join("ONNX-Models", f"model.onnx")
dtype = torch.float16 if halved else torch.float32
inputs = inputs_.input_values
masks = inputs_.attention_mask
model.eval()
if export_onnx :
# dataType= torch.float16 if halved else torch.float32
if not os.path.exists(ONNXmodelDir):
os.makedirs("ONNX-Models",exist_ok = True)
dummy_input = torch.unsqueeze(inputs[0] , dim=0)
dummy_masks = torch.unsqueeze(masks[0].to(dummy_input.dtype) , dim=0)
torch.onnx.export(
model,
(dummy_input, dummy_masks),
ONNXmodelDir,
# f"model.onnx",
input_names=["input", "masks"],
output_names=["output"],
dynamic_axes={"input": {0: "batch_size", 1: "sequence_length"},
"masks": {0: "batch_size", 1: "sequence_length"},
"output": {0: "batch_size", 1: "sequence_length"}},
opset_version=11, # You can adjust the opset version based on your needs
)
print ("Finished saving the ONNX model")
if halved and not os.path.exists(ONNX_Half_Dir):
model = onnx.load(ONNXmodelDir)
model_fp16 = float16.convert_float_to_float16(model)
onnx.save(model_fp16, ONNX_Half_Dir)
del model_fp16
options = onnxruntime.SessionOptions()
options.enable_profiling = True
provider = 'CPUExecutionProvider' if device == 'cpu' else 'CUDAExecutionProvider'
Dir = ONNX_Half_Dir if halved else ONNXmodelDir
model = onnxruntime.InferenceSession(Dir
, sess_options=options
, providers= [provider])
input_name = model.get_inputs()[0].name
mask_name = model.get_inputs()[1].name
output_name = model.get_outputs()[0].name
inputs = [[output_name], {input_name: inputs.to(dtype).numpy(),
mask_name: inputs.to(dtype).numpy()}]
print("#############################\n Finished loading the ONNX model and the Inputs\n#############################")
#transfer the model and data to cpu or gpu
else:
# if not halved:
#
model = model.to(torch.float32)
model = model.half() if halved else model
inputs = inputs.half() if halved else inputs
masks = masks.half() if halved else masks
model = model.to(device)
inputs = [inputs.to(device), masks.to(device)]
print("#############################\nFinished loading the Pytorch model and the Inputs\n#############################")
return model, inputs
# Function to perform inference and measure time and memory usage
def inference(model, inputs, device, halved, batch_size, export_onnx=False):
fileNames , inputs = inputs
gpu_first_stat = get_gpu_stats()
result = { 'time': 0,
# 'gpu_memory_reserved_amount': [getMB(torch.cuda.memory_reserved()) if device == 'cuda' else 0],
# 'gpu_memory_util_amount': [getMB(torch.cuda.memory_allocated()) if device == 'cuda' else 0],
'gpu_utilization':[gpu_first_stat[0]],
'gpu_memory_used':[gpu_first_stat[1]],
'gpu_memory_total':[gpu_first_stat[2]],
'cpu_memory_util_percent': [round(psutil.virtual_memory().percent,3)],
'cpu_util_percent': [round(psutil.cpu_percent(),3)],
'cpu_memory_util_amount': [getMB(psutil.virtual_memory().used)],
'decoder_time':[],
'done': False}
# Initialize the thread for memory monitoring
mode = "onnx" if export_onnx else "pytorch"
memory_thread = threading.Thread(target=monitor_memory, args=(device, result))
memory_thread.start()
model_time_track = []
decoder_time_track = []
# Inference
if export_onnx:
for _ in range(5):
# Perform inference 10 times for more accurate timing
start_time = time.time()
logits = model.run(inputs[0], inputs[1] )
model_time_track.append(time.time() - start_time)
predicted_ids = logits[0].argmax(axis=-1)
decoder_start_time = time.time()
predicted_sentences = processor.batch_decode(predicted_ids)
decoder_time_track.append(time.time() - decoder_start_time)
else:
inputs, masks = inputs
for _ in range(5):
with torch.no_grad():
# Perform inference 10 times for more accurate timing
mdoel_start_time = time.time()
logits = model(inputs, attention_mask =masks).logits
model_time_track.append(time.time() - mdoel_start_time)
decoder_start_time = time.time()
predicted_ids = torch.argmax(logits, dim=-1)
predicted_sentences = processor.batch_decode(predicted_ids)
decoder_time_track.append(time.time() -decoder_start_time)
del masks
result['outputs'] = predicted_sentences
result["filenames"] = fileNames
# Stop memory monitoring thread
result
result['done'] = True
del model
del inputs
memory_thread.join()
model_time, decoder_time = round(np.median(model_time_track[2:]),4) ,round(np.median(decoder_time_track),4)
# Calculate time and save results
result = {key: value for key,value in result.items() if isinstance(value, list) and len(value) > 1}
result = manage_dictionary_lengths(result)
overall_stats = [
round(interval*np.sum(result['cpu_util_percent']),2)
, round(interval*np.sum(result['gpu_memory_used']),1)
, round (interval*np.sum(result['gpu_utilization']), 2)
, round(interval*np.sum(result['cpu_memory_util_percent']),1)
, round(interval*np.sum(result['cpu_memory_util_amount']),1 )
]
folder_name = f'Inference_logs_{mode}_{device}_halved_{halved}_batch_{batch_size}'
overall_results[folder_name] = [ mode, device, halved, batch_size
, model_time, decoder_time
,
overall
_stats[0]
, overall_stats[1]
, overall_stats[2]
, overall_stats[3]
, overall_stats[4]
, round(overall_stats[0] / batch_size, 4)
, round(overall_stats[1] / batch_size, 4)
, round(overall_stats[2] / batch_size, 4)
, round(overall_stats[3] / batch_size, 4)
, round(overall_stats[4] / batch_size, 4)
, round(model_time / batch_size, 5)
, round(decoder_time / batch_size, 5)
]
plot_individual_results(result,mode, device, halved, batch_size, [model_time_track], [decoder_time_track] ,os.getcwd())
# Example usage
if name == "__main__":
# parser = argparse.ArgumentParser(description="ONNX Inference Benchmark Script")
# parser.add_argument("--modelDir", type=str, default="../ImanSavedData", help="Location of the model folder")
# args = parser.parse_args()
# model_dir = args.modelDir
test_path = "Samples"
speech_arrays = []
fileNames = [f for f in os.listdir(test_path) if f.endswith('.wav') or f.endswith('.mp3')]
# fileNames = ['11.wav']
paths = [os.path.join(test_path,f) for f in fileNames]
speech_arrays = [librosa.load(path, sr=16_000)[0] for path in paths]
# Define configurations
# devices = ['cuda'] if torch.cuda.is_available() else ['cpu']
devices = ['cuda']#,'cpu']
halved_options = [ False]#True,
batch_sizes = [1,5,11] # Adjust based on your needs
model_dir = "./model/"
# Perform inference for different configurations
for onnxmode in [ True, False]:#
for device in devices:
for halved in halved_options:
for batch_size in batch_sizes:
model_dir = "./model/"
model_dir = model_dir#+'_half' if halved else model_dir
processor = Wav2Vec2Processor.from_pretrained(model_dir)
inputs = processor(speech_arrays[:batch_size], sampling_rate=16_000, return_tensors="pt", padding="max_length",max_length =240320, truncation= True )
# Load and prepare the model
halved = False if device=='cpu' else halved
model, inputs = load_and_prepare_model_inputs(model_dir, inputs, export_onnx=onnxmode, halved=halved, device=device)
# Perform inference
fileNamesTemp = fileNames[:batch_size]
inference(model, [fileNamesTemp , inputs], device, halved, batch_size, export_onnx=onnxmode)
custom_index = [
"mode","device", "halved", "batch-size" , "model-time" , "decoder-time" ,
"cpu-util-percent", "gpu-memory-used", "gpu-utilization",
"cpu-memory-util-percent", "cpu-memory-util-amount",
'cpu-util-percent-batch-size-gain', "gpu-memory-used-batch-size-gain" , "gpu-utilization-batch-size-gain",
"cpu-memory-util-percent-batch-size-gain", "cpu-memory-util-amount-batch-size-gain",
"model-time-batch-size-gain" , "decoder-time-batch-size-gain"
]
df = pd.DataFrame(overall_results, index=custom_index)
df.to_excel('overall_logs.xlsx',index=True ) #float_format='%.4f' ,index=True )
print(f"**** device:{device}-halfed:{halved}-batchsize:{batch_size}, isONNX:{onnxmode}-- Done *****\n\n")
and Here are the results