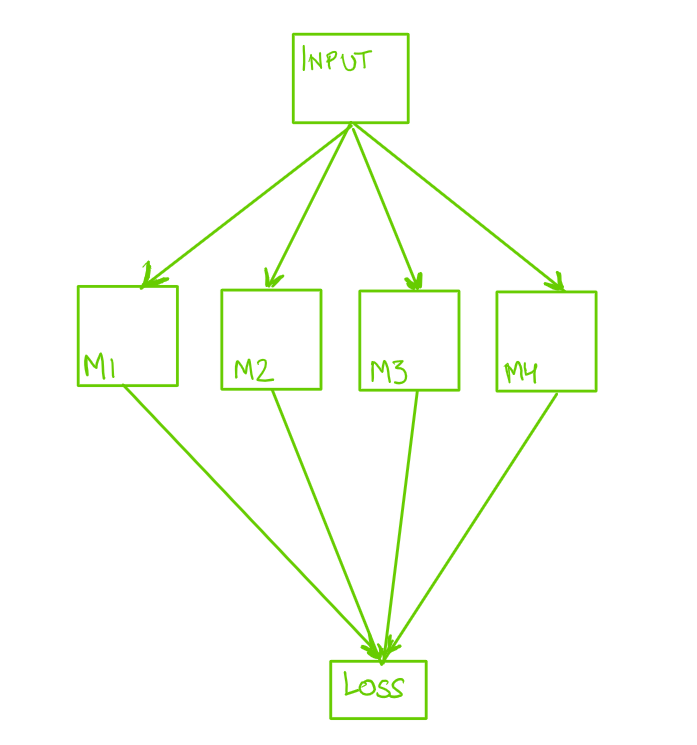
Q1. Since M1 through M4 are independent and at the same level in computation graph, will backward() compute the gradients for them in parallel? (Anything else will involve sequential operations and be suboptimal.) Please share a reference from original docs if they mention this.
Q2. What happens if there are too many nodes at the same level and for some compute / memory constraints a parallel backward() cannot be executed?
I’m wondering why does this not make PyTorch very slow (i.e. processing modules at the same level sequentially)? Shouldn’t parallelizing this give a big speedup?
It depends a lot on how big the modules are. The most common use cases have very large modules that already saturate a single device fully when they run. So there is no opportunity to run multiple modules at the same time on the same device.
This is why we parallelize on different devices but not for a single device and this is not slowing down the common use case.