The Concordance Correlation Coefficient is defined as follows:
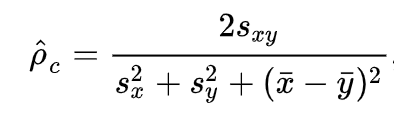
The loss function computed between the labels and the outputs of the model is L = 1 - CCC
My question is: if the samples have temporal dependency (in this case they are clips from the same audio which will probably have more similar labels), does it matter whether to shuffle the training set before training? And will the batch size be very critical?