Hi, The following fx graph is after backend compile, and there are two fused partitions.
def forward(self, arg0_1: "f32[16, 16, 1, 1]", arg1_1: "f32[16, 16, 1, 1]", arg2_1: "f32[1, 16, 8, 8]"):
fused_1: "f32[1, 16, 8, 8]" = self.fused_1(arg2_1, arg0_1, arg1_1); arg2_1 = arg1_1 = None
_to_copy: "f32[1, 16, 8, 8]" = torch.ops.aten._to_copy.default(fused_1, …, device = device(type='cpu')); fused_1 = None
relu: "f32[1, 16, 8, 8]" = torch.ops.aten.relu.default(_to_copy); _to_copy = None
_to_copy_1: "f32[1, 16, 8, 8]" = torch.ops.aten._to_copy.default(relu, …, device = device(type='hpu', index=0)); relu = None
fused_0: "f32[1, 16, 8, 8]" = self.fused_0(_to_copy_1, arg0_1); _to_copy_1 = arg0_1 = None
_to_copy_2: "f32[1, 16, 8, 8]" = torch.ops.aten._to_copy.default(fused_0, …, device = device(type='cpu')); fused_0 = None
relu_1: "f32[1, 16, 8, 8]" = torch.ops.aten.relu.default(_to_copy_2); _to_copy_2 = None
_to_copy_3: "f32[1, 16, 8, 8]" = torch.ops.aten._to_copy.default(relu_1, …, device = device(type='hpu', index=0)); relu_1 = None
return (_to_copy_3,)
When I run the compiled module, I saw that:
- fused_1 is freed before allocating _to_copy_1
- fused_0 is freed before allocating _to_copy_3
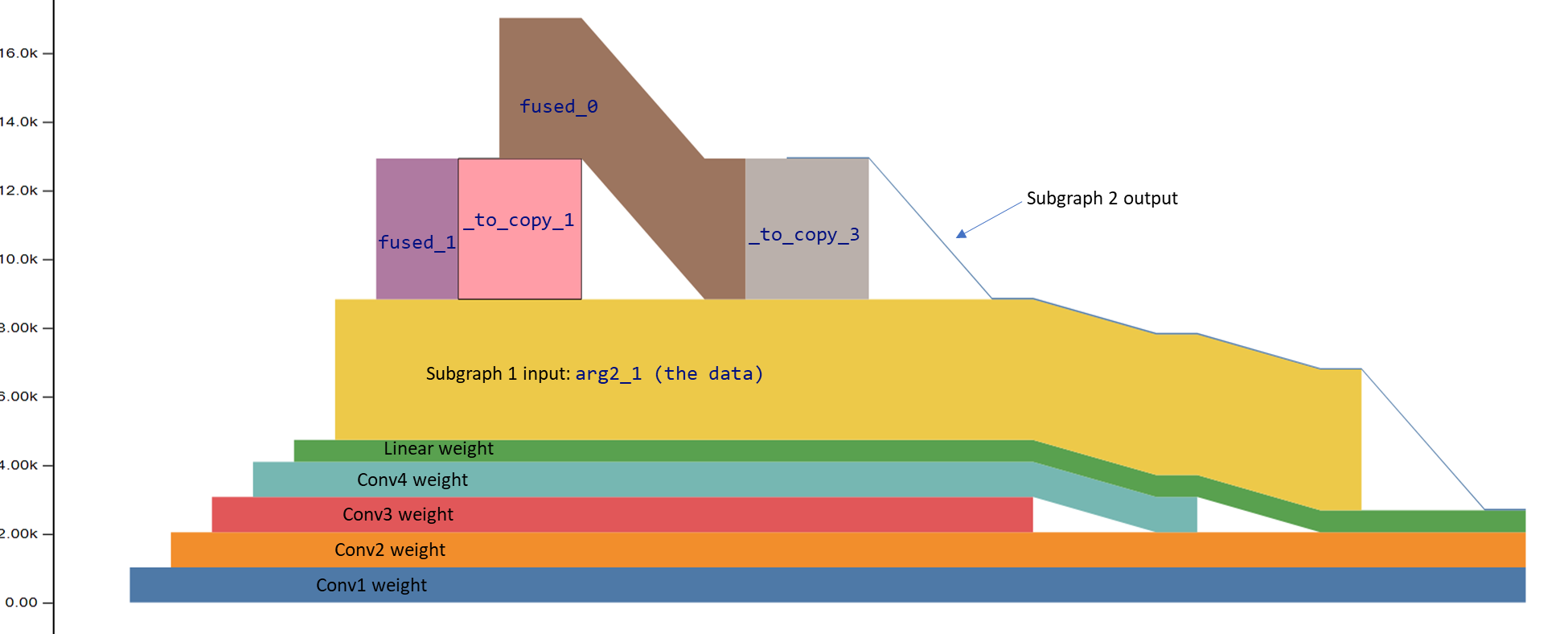
It seems that pytorch has automatically freed the fused_1 and fused_0 after its last use. So my question is where this optimization happens? could anyone help to answer the question? Thanks~