Pytorch has its function torch.qr() to implement QR decomposition. For instance, let A be a matrix with size of 3000*60. I have installed Magma as LAPACK support. If I place A on CPU by A.cpu(), to compute torch.qr(A) for 100 times, it will take about 0.4 second. However, when I place A on GPU by A.cuda(), it will take 1.4 seconds. I thought running on GPU should be faster than running on CPU. Can anyone explain this phenomenon to me? Thanks a lot!
1 Like
One possible reason is that it takes time to send the data to the GPU. When a calculation is very quick as in this case there are some other small time costs that could add up. If you want to check whether what I am saying is correct try and do a QR decomposition on a matrix that takes a few minutes to run on a cpu and then try it on the GPU.
1 Like
Thank you for your reply! Actually I want to compute the QR decompositon of small matrices many times instead of a big matrix one time. So I guess what you mean is that torch.qr() on GPU is more suitable to do QR decomposition of a big matrix?
Not necessarily. I am not an expert in this area. However, I believe it depends on how you are passing the small matrices to the GPU. There is probably an upfront cost of sending something to a GPU, if you manage to send all the small matrices at once it might be quicker in the GPU. If you have something like a for loop where at each iteration you send the individual matrix it will probably be slower in GPU than CPU.
1 Like
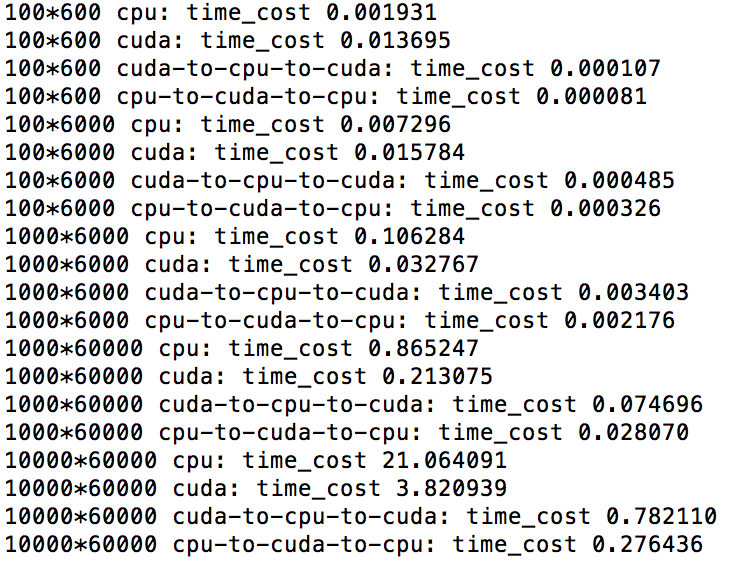
I test the time to transfer data between CPU and GPU. And from the result, it seems that the time cost of transferring data can be neglected compared to the time to do the QR decomposition. It is weird that GPU performs much worse on QR decomposition of small matrices compared to CPU. As in the picture, the time to do QR over a 100600 matrix is close to the time to do QR over a 1006000 matrix.
How did you measure the transfer time?
Note that CUDA calls are asynchronous, so that the data transfer and processing will be performed in the background.
If you want to time the transfer time, you should synchronize the calls with: torch.cuda.synchronize():
a = torch.randn(...)
torch.cuda.synchronize()
t0 = time.time()
a = a.to('cuda:0')
torch.cuda.synchronize()
t1 = time.time()
2 Likes
Based on your suggestion of measuring transfer time, my current code is
ns=[600,6000,6000,60000,60000]
for i, p in enumerate(ps):
n=ns[i]
A=torch.rand(p,n).cpu()
torch.cuda.synchronize()
t0 = time.time()
A.qr()
torch.cuda.synchronize()
t1 = time.time()
t=t1-t0
print('%d*%d cpu: time_cost %f'%(p,n,t))
A=torch.rand(p,n).cuda()
torch.cuda.synchronize()
t0 = time.time()
A.qr()
torch.cuda.synchronize()
t1 = time.time()
t=t1-t0
print('%d*%d cuda: time_cost %f'%(p,n,t))
A = torch.randn(p,n).cpu()
torch.cuda.synchronize()
t0 = time.time()
A = A.to('cuda:0')
torch.cuda.synchronize()
t1 = time.time()
t=t1-t0
print('%d*%d cpu-to-cuda: time_cost %f'%(p,n,t))
A=torch.rand(p,n).cuda()
torch.cuda.synchronize()
t0 = time.time()
A=A.cpu()
torch.cuda.synchronize()
t1 = time.time()
t=t1-t0
print('%d*%d cuda-to-cpu: time_cost %f'%(p,n,t))
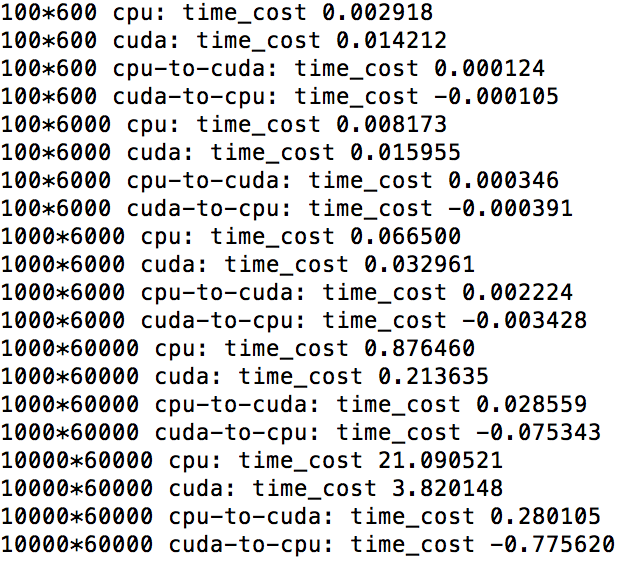
And the result is the following picture:
2 Likes
Weird that cpu / cuda time_cost for 100*6000 matrix. Cuda is at least 2x slower than gpu.
Confirmed bug ! https://github.com/pytorch/pytorch/issues/22573#issuecomment-509657100
1 Like