But I encounter the error
RuntimeError: Only Tensors of floating point and complex dtype can require gradients
I believe the requires_grad is True by default
Is there no way to diff the int32 (default) or I am doing something wrong?
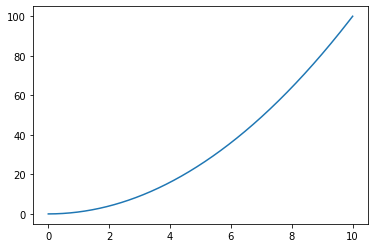
I wouldn’t know how and if gradients are defined on “integer functions”. E.g. just take a simple example of f(x) = x**2.
For floating point numbers you would see:
and can draw the gradient directly into the plot.
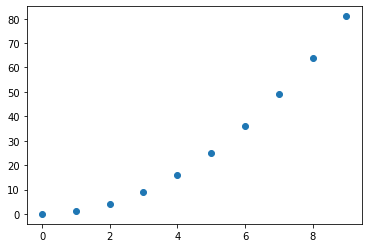
But I guess this is how this simple function would look if only integers are used:
Would this mean that the gradient is everywhere 0 besides at the dots (where it would then be +/- Inf)?
If so, then I don’t think it would make sense to allow Autograd to accept integer values.
In case you are expecting integer outputs, it might be better to round the result.
Also, I’m sure other users such as @KFrank, @tom, and @albanD might have a better explanation.
Thanks, another following question, maybe I am wrong, so the AD in PyTorch is doing finite difference? so you need it to be continuous? I am new to AD, a silly question, why can’t it perform dx**2/dx=2x
To comment on the dx**2/dx = 2x question, AD isn’t computing a symbolic expression for the gradient. It’s basically using the chain rule to calculate your derivative directly. If you want to read a paper on it, I’d recommend Automatic Differentiation in Machine Learning: a Survey which will explain to you why AD isn’t symbolic differentiation nor numerical differentiation
If you do want an expression you could use the functorch library, although that’s a bit more complicated than standard PyTorch. An example for your function would be something like this,
import torch
from functorch import grad, vmap
def f(x):
return x**2
x = torch.arange(1,5,dtype=torch.float32) #dummy input
df_dx = grad(f) #creates explicit function via reverse-mode AD
vmap(df_dx, in_dims=(0))(x) #returns tensor([2., 4., 6., 8.])
The problem is not with how we compute the gradient but the definition of gradients itself.
Mathematically, for gradients to be defined, you need a continuous function (at least locally).
Like I am saving my weights in a dict as integer but when I load them using .load_state_dict() function it doesn’t work they got converted to floats and if I try to convert them to int using .to(torch.uint8) on the model I have an error any suggestions?