Hi everyone!
I am training two models end-to-end and want to fuse the last layers of both models using a dot product between tensors.
I have tried concatenation, element-wise addition, and matrix multiplication so far.
But I’m having trouble with the dot product!
Here’s my model, which is a simple MLP with three hidden layers performing concatenation. I’d like to replace the concatenation operation with a dot product.
import torch.nn as nn
class MulticlassClassification(nn.Module):
def __init__(self, num_feature, num_class=3):
super(MulticlassClassification, self).__init__()
self.layer_1 = nn.Linear(num_feature, 500)
self.layer_2 = nn.Linear(500, 500)
self.layer_3 = nn.Linear(500, 256)
self.layer_out = nn.Linear(256, num_class)
self.relu = nn.ReLU()
self.dropout = nn.Dropout(p=0.3)
def forward(self, x):
x = self.layer_1(x)
x = self.relu(x)
x = self.layer_2(x)
x = self.relu(x)
x = self.dropout(x)
x = self.layer_3(x)
x = self.relu(x)
x = self.dropout(x)
x = self.layer_out(x)
return x
model_EHR = MulticlassClassification(3)
model_G = MulticlassClassification(79)
class MyEnsemble(nn.Module):
def __init__(self, model_EHR, model_G, nb_classes=3):
super(MyEnsemble, self).__init__()
self.model_EHR = model_EHR
self.model_G = model_G
# Remove last linear layer
self.model_EHR.layer_out = nn.Identity()
self.model_G.layer_out = nn.Identity()
# Create new classifier
self.layer_out = nn.Linear(512, nb_classes)
def forward(self, x1, x2):
x1 = self.model_EHR(x1)
x1 = x1.view(x1.size(0), -1) #this one if I wnat to perform multiplication
x2 = self.model_G(x2)
x2 = x2.view(x2.size(0), -1)
x = torch.cat((x1, x2), dim=1)
x = self.layer_out(F.relu(x))
return x
def model() -> MyEnsemble:
model = MyEnsemble(model_EHR, model_G)
return model
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
from torchsummary import summary
model = model()
print(model)
model.to(device=DEVICE,dtype=torch.float)
summary(model, [(1, 3), (1,79)]) # dimension of first model (1, 3), dimension of second model (1,79)
Output of model.summary
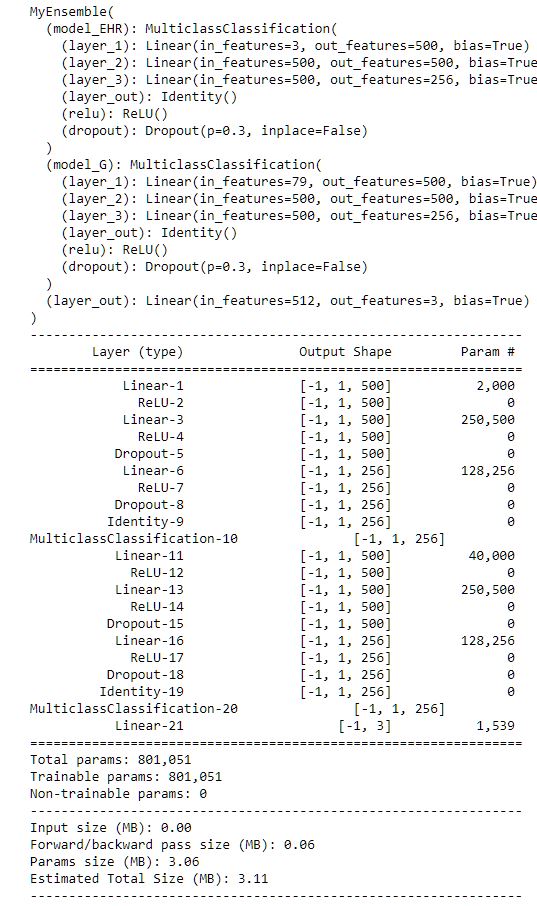
I tried this approach, which worked for randomly generated tensors but not for my model.
x1=torch.randn([1, 256])
x2=torch.randn([1, 256])
Transpose_x2 = torch.transpose(x2, 0, 1)
fusion =torch.bmm(x1.unsqueeze(0),Transpose_x2.unsqueeze(0))
Any suggestion, please?