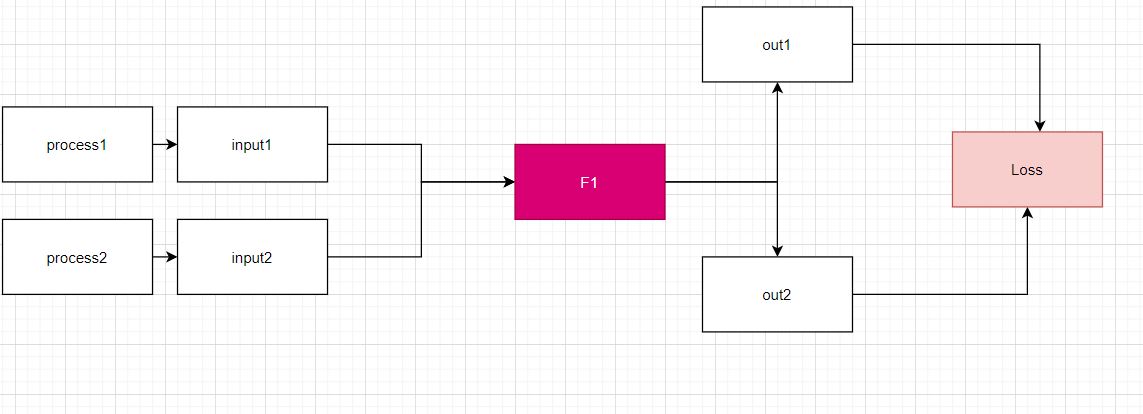
I have a doubt regarding what’s going on behind the implementation of the architecture shown in the figure.
In the figure outputs 1 and 2 come from inputs 1 and 2 respectively.
Assume that we detach output 1 and set requires_grad = False for F1 . It is observed empirically that loss.backward() works however based on the documentation gradient computation will stop after reaching F1 in a backward pass . So how exactly are the gradients being updated ?
Will there be any difference if we set requires_grad = True for F1 ?
Suppose now that output 1 is not detached and the loss is backpropagated this time .
Firstly , how exactly is the resultant gradient for the loss computed ?
Is it the sum of the partial derivatives we get with respect to outputs 1 and 2 or is it calculated in some other manner ?
Lastly if we set requires_grad = False for process 1 and input 1 and do the loss computation again will the gradients for output 2 have the same value as when output 1 was detached ?
If F1 is a layer/module with at least one parameter, you can view it as a function: out = F1(input, F1.param). I’m assuming you’re asking about applying it multiple times. Basically, input.detach() or F1.param.requires_grad=False disables only one of backprop paths; if you freeze a parameter, dOut/dInput backprop may continue, dOut/dParam stops.
for any X with requires_grad==True, as dLoss/dX = dLoss/dOut * dOut/dX
yes, you sum gradients if backprop reaches the same node (i.e. F1.param) multiple times.
Not sure I understand this, dLoss(out2,…)/dOut2 won’t depend on out1 if you don’t combine out1 and out2.
A little bit of clarification for my last doubt what I meant was is detaching output 1 equivalent to setting requires_grad = False in input 1 for example ?
Hi , regarding your explanation that dOut/dInput backprop may continue while the other path is stopped. I did a little experiment , initialize a simple linear layered NN with some random input , output and target for loss computation. If I wrap the model in torch.nograd then backward() will show an error as no gradients can be passed . Now , suppose if I set requires_grad = False backprop is computed and I get some value a I get the same value even when I set requires_grad = True . Acc to the forums (No_grad() vs requires_grad) , requires_grad makes sense only for individual tensors and not for model as a whole as backprop will take place regardless . Thus , I am confused by your explanation that dOut/dparam will stop
that gradient is only used to set param.grad (leaf variable): param.grad = dLoss/dParam = (dLoss/dOut) * (d/dParam F1(input, param)). param.requires_grad = False blocks the second term and you’ll have no param.grad. Backprop path for input is not affected, as it proceeds via d/dInput F1(input,param)