Hello, sorry if this has been posted again and again, but I have yet another DQN agent that won’t learn.
Context : DQN agent with replay buffer on Farama’s Cartpole-v1
Problem : I tweaked the agent a lot, lately it will stagnate around 10 steps per episode (until termination or truncation) and once in a while it will have a peak at like 90-ish steps. Example here :
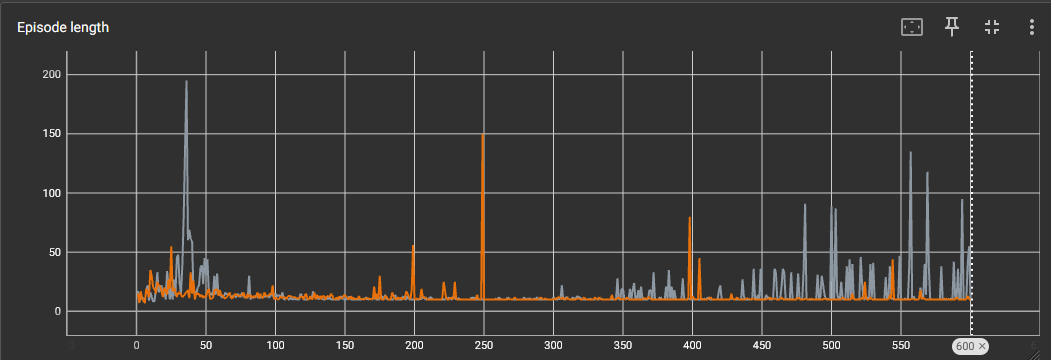
However it depends really. The persistent problem is that it doesn’t do more than 10 steps per episode on average.
The “Critic” module is just a 3 layer ReLU-MLP with hidden sizes : 5x128, 128x128, 1x128
here is the learning loop:
def learn(
self,
replay_buffer: ReplayBuffer,
) -> None:
super().learn()
batch_s, batch_a, batch_r, batch_s_, batch_dw = replay_buffer.sample(
self.batch_size, self.device
) # Sample a batch
self.optimizer.zero_grad()
target = None
with torch.no_grad():
func = lambda s: self.critic_target(
s.repeat(self.actions.shape[0], 1), self.actions
) # 1 logit / action for 1 state
# fmt: off
target = torch.func.vmap(func, in_dims=0)(batch_s_).max(1).values.view(-1, 1) # bs x 1
terminal = batch_dw == True
target[terminal] = batch_r[terminal]
target[~terminal] = batch_r[~terminal] + self.GAMMA * target[~terminal]
loss = self.Loss(target, self.critic(batch_s, batch_a))
loss.backward(retain_graph=False)
self.optimizer.step()
return loss.item()
Here is the simulation loop :
while num_episodes < max_num_episodes:
# epsilon-greedy
sample = np.random.random()
eps_threshold = scheduler.step()
writer.add_scalar("Eps_threshold", eps_threshold, steps_done)
steps_done += 1
a = agent.choose_action(s)[0] if sample > eps_threshold else env.action_space.sample()
if sample < eps_threshold:
chose_random += 1
# execute action and observe reward and next state
s_, r, terminated, truncated, _ = env.step(a)
reward += r
replay_buffer.push(s, a, r, s_, terminated or truncated)
# if steps_done >= batch_size:
writer.add_scalar("Loss", agent.learn(replay_buffer), steps_done)
if terminated or truncated:
num_episodes += 1
s, _ = env.reset(seed=SEED)
writer.add_scalar("Episode length", ep_len, num_episodes)
writer.add_scalar("Total Reward per episode", reward, num_episodes)
writer.add_scalar("Number of times random action was chosen / Total number of actions", chose_random / num_episodes, num_episodes)
chose_random = 0
pbar.update(1)
pbar.set_description(f"Reward {reward} Duration {ep_len} Episode {num_episodes}/{max_num_episodes}")
reward = 0.
ep_len = 0
else:
s = s_
ep_len += 1
#if (steps_done + 1) % update_freq == 0:
agent.reset_target_critic_params()
The parts “if steps_done >…” and “if (steps_done+1)%…” are commented because I tried with and without them and nothing changes.
Hyperparameters :
discount_factor = 0.99
tau for polyak averaging = 0.005
learning_rate = 1e-4
optimizer = Adam(weight_decay=0.2) and also tried AdamW(amsgrad=True)
loss = MSELoss but also tried SmoothL1Loss
Thank you for your time and answers in advance !
P.S. Small detail : most DQN networks will take a state and output n_actions values. Mine takes a state and an action and outputs the corresponding value (hence the 1 in 1x128). Therefore, I duplicate the action along the dim=0 and then evaluate the network in ([[s],[s],[s],…],[[a1],[a2],[a3],…]) and take the max on dim=1 for learning and the argmax on dim=0 for actions.