Hey everyone!
I’m trying to reproduce the results of the Nature Atari paper. I have started with the dqn PyTorch tutorial for the algorithm and expanded on that with some environment wrappers for the preprocessing. While it does learn, I can not get it to consistently play better.
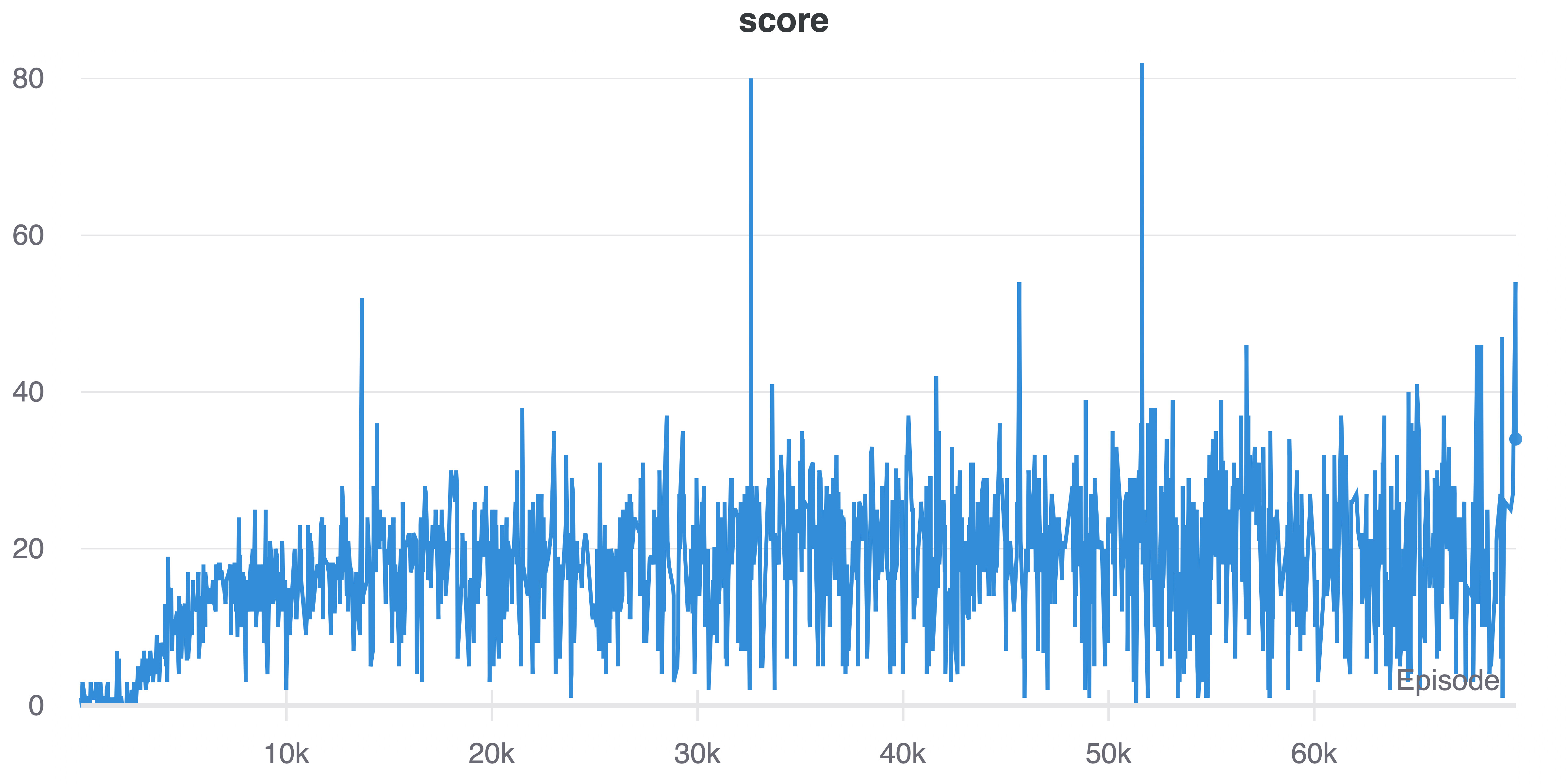
While the training score does go up a little but, it also falls down to almost zero most of the time. Note that this graph is the max(0, clipped_reward):
Whenever I update the target net, I try one test run in which I log the max(0, unclipped_reward):
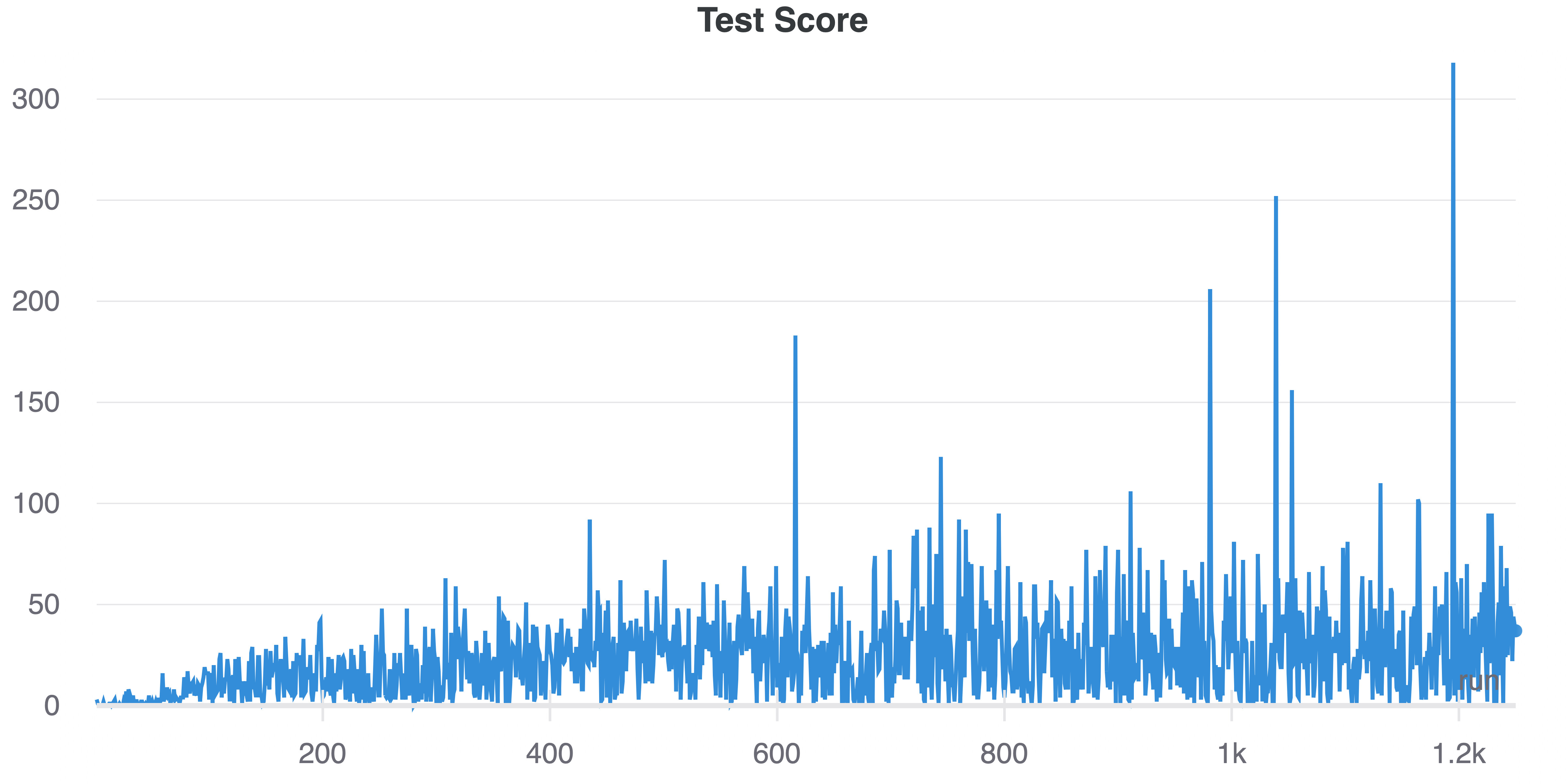
Again, while some high scores are achieved, more runs actually achieve a score of 0 or something the likes.
Here is my algorithm:
or here as a Gist
import pickle
import gym
import math
import random
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image
import click
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision.transforms as T
from zennit.composites import COMPOSITES
import utils
from ReplayMemory import ReplayMemory, Transition
from EnvironmentWrappers import FrameStackingEnv
from pickle import dumps, loads
from model import DQN, LinearSchedule
from tqdm import tqdm
import os
import wandb
# matplotlib.use('TkAgg')
os.environ['KMP_DUPLICATE_LIB_OK'] = 'True'
BATCH_SIZE = 32
GAMMA = 0.99
TARGET_UPDATE_STEPS = 10000
# TARGET_UPDATE_STEPS = 5
REPLAY_MEMORY_SIZE = 1000000
# REPLAY_MEMORY_START_SIZE = 50000
REPLAY_MEMORY_START_SIZE = 32
UPDATE_FREQUENCY = 4
NO_OP_MAX = 30
MAX_FRAME_COUNT = 50000000
LR = 0.00025
GRADIENT_MOMENTUM = 0.95
# SQUARED_GRADIENT_MOMENTUM = 0.95
MIN_SQUARED_GRADIENT = 0.01
SAVE_STATE_SCORE_INTERVAL = 4
@click.command()
@click.option('--seed', type=int)
@click.option('--cpu/--gpu', default=False)
@click.option('--env', type=str, default='BreakoutNoFrameskip-v4')
@click.option('--params', type=click.Path(dir_okay=False))
# @click.option('--wandb', default=True)
def main(seed, cpu, env, params):
if seed is not None:
torch.manual_seed(seed)
steps_done = 0
device = torch.device('cuda:0' if torch.cuda.is_available() and not cpu else 'cpu')
print(device)
test_env = gym.make(env)
env = gym.make(env)
env = FrameStackingEnv(env, random_start=NO_OP_MAX)
test_env = FrameStackingEnv(test_env, random_start=0)
resize = T.Compose([T.ToPILImage(),
T.Resize((84, 84), interpolation=Image.CUBIC),
T.ToTensor()])
def get_screen(env, transform=True):
_, screen = env.render(mode='rgb_array')
screen = screen.transpose((2, 0, 1))
# env.render(mode='human')
screen = torch.from_numpy(screen)
if transform:
return resize(screen)
else:
return screen
policy_net = DQN((4, 84, 84), env.action_space.n, device).to(device)
if params is not None:
policy_dict = torch.load(params, map_location='cuda:0' if torch.cuda.is_available() else 'cpu')
policy_net.load_state_dict(policy_dict)
target_net = DQN((4, 84, 84), env.action_space.n, device).to(device)
target_net.load_state_dict(policy_net.state_dict())
target_net.eval()
optimizer = optim.RMSprop(policy_net.parameters(), lr=LR, momentum=GRADIENT_MOMENTUM, eps=MIN_SQUARED_GRADIENT)
memory = ReplayMemory(100000)
def optimize_model():
if len(memory) < BATCH_SIZE:
return
transitions = memory.sample(BATCH_SIZE)
batch = Transition(*zip(*transitions))
# Compute a mask of non-final states and concatenate the batch elements
non_final_mask = torch.tensor(tuple(map(lambda s: s is not None, batch.next_state)), device=device,
dtype=torch.bool)
non_final_next_states = [s for s in batch.next_state if s is not None]
if len(non_final_next_states) > 0:
non_final_next_states = torch.cat([s for s in batch.next_state if s is not None])
state_batch = torch.cat(batch.state)
action_batch = torch.cat(batch.action)
reward_batch = torch.cat(batch.reward)
# Compute Q(s_t, a) - the model computes Q(s_t), then we select the
# columns of actions taken. These are the actions which would've been taken
# for each batch state according to policy_net
# policy net computes Q(s_t), the index of the taken action is in action_batch tensor
# now the state_action values are collected by gathering the state values from the result of policy_net
# using the 'gather' function, which selects values from a tensor along the given dimension and the indices
# given in the 'indices' tensor (which in this case is 'action_batch')
state_action_values = policy_net(state_batch).gather(1, action_batch)
# Compute V(s_{t+1}) for all next states.
# Expected values of actions for non_final_next_states are computed based
# on the "older" target_net; selecting their best reward with max(1)[0].
# This is merged based on the mask, such that we'll have either the expected
# state value or 0 in case the state was final.
next_state_values = torch.zeros(BATCH_SIZE, device=device)
# this time, we get the actual values, which is why we use .max(1)[0]
if len(non_final_next_states) > 0:
next_state_values[non_final_mask] = target_net(non_final_next_states).max(1)[0].detach()
# Compute the expected Q values (reward + gamma q_pi)
expected_state_action_values = reward_batch + (GAMMA * next_state_values)
criterion = nn.SmoothL1Loss()
loss = criterion(state_action_values, expected_state_action_values.unsqueeze(1))
optimizer.zero_grad()
loss.backward()
# Gradients are clamped to make training more stable:
# "Because the absolute value loss function |x| has a derivative of -1 for all negative values of x and a derivative of 1 for all positive values of x,
# clipping the squared error to be between -1 and 1 corresponds to using an absolute value loss function for errors outside of the (-1,1)"
for param in policy_net.parameters():
param.grad.data.clamp_(-1, 1)
optimizer.step()
def run_test_episode(model, env, max_steps=10000): # -> reward, movie
_state = env.reset().unsqueeze(0)
idx = 0
_done = False
_reward = 0
movie_frames = []
x_vals = []
meanings = env.unwrapped.get_action_meanings()
action_vals = [[] for _ in meanings]
while not _done and idx < max_steps:
movie_frames.append(get_screen(env, False))
_action, all_values = model.select_action(_state, steps_done, eps=0.05, log=True)
_state, r, _done, _ = env.step(_action)
_state = _state.unsqueeze(0)
_reward += max(0, r)
x_vals.append(idx)
for i, l in enumerate(action_vals):
l.append(all_values[0][i].item())
idx += 1
log_state_action_values(x_vals, action_vals, meanings)
return _reward, np.stack(movie_frames, 0)
# prefill Replay Memory with REPLAY_START_SIZE frames of random actions
tq = tqdm()
tq.set_description("Filling initial Replay Memory")
state = env.reset(fill=True).unsqueeze(0)
while steps_done < REPLAY_MEMORY_START_SIZE:
tq.update(1)
steps_done += 1
action = torch.tensor([[env.action_space.sample()]], device=device)
obs, reward, done, info = env.step(action.item())
reward = torch.tensor([reward], device=device)
if not done:
next_state = obs.unsqueeze(0)
else:
next_state = None
# Store the transition in memory
memory.push(state, action, next_state, reward)
if done:
state = env.reset(fill=True).unsqueeze(0)
# else:
# state = next_state
tq.reset()
steps_done = 0
update_steps_done = 0
tq.set_description("Training")
state = env.reset().unsqueeze(0)
score_sum = 0
current_score_interval = 1
while steps_done < MAX_FRAME_COUNT:
tq.update(1)
steps_done += 1
action = policy_net.select_action(state, steps_done)
lives = env.ale.lives() # get lives before action
obs, reward, done, info = env.step(action.item())
reward = torch.tensor([reward], device=device)
reward.data.clamp_(-1, 1)
score_sum += max(0, reward.item())
# if we did not lose a life and the episode is not done
if not done and lives == env.ale.lives():
next_state = obs.unsqueeze(0)
else:
next_state = None
# if steps interval and we haven't already saved this state
if score_sum > current_score_interval and score_sum % SAVE_STATE_SCORE_INTERVAL == 0:
current_score_interval = score_sum
save_snapshots_to_disk(*env.snapshot(), score_sum)
# Store the transition in memory
memory.push(state, action, next_state, reward)
if steps_done % UPDATE_FREQUENCY == 0:
optimize_model()
update_steps_done += 1
if update_steps_done % TARGET_UPDATE_STEPS == 0:
# update target net parameters
target_net.load_state_dict(policy_net.state_dict())
torch.save(policy_net.state_dict(), f'{checkpoint_dir}/policy_net_{steps_done}.pth')
test_reward, frames = run_test_episode(policy_net, test_env)
if done:
wandb.log({'score': score_sum})
score_sum = 0
state = env.reset().unsqueeze(0)
else:
state = obs.unsqueeze(0)
print('Complete')
env.close()
wandb.finish()
if __name__ == '__main__':
main()
and my wrappers are here
import gym
import numpy as np
import cv2
import torch
import collections
import torchvision.transforms as T
from PIL import Image
class FrameStackingEnv(gym.Wrapper):
def __init__(self, env, num_stack=4, random_start = 30, transform=T.Compose([T.ToPILImage(),
T.Resize((84, 84), interpolation=Image.CUBIC),
T.ToTensor()])):
super().__init__(env)
self.env = env
self.n = num_stack
self.transform = transform
self.random_start = random_start
self.last_unprocessed_frame = None
self.buffer = collections.deque(maxlen=num_stack)
@staticmethod
def _preprocess_frame(first_frame, second_frame):
image_r = np.maximum(first_frame[:, :, 0], second_frame[:, :, 0])
image_g = np.maximum(first_frame[:, :, 1], second_frame[:, :, 1])
image_b = np.maximum(first_frame[:, :, 2], second_frame[:, :, 2])
# openCV uses BGR order of color channels
image = np.stack((image_b, image_g, image_r), axis=-1)
img_yuv = cv2.cvtColor(image, cv2.COLOR_BGR2YUV)
y, _, _ = cv2.split(img_yuv)
return torch.from_numpy(y)
def reset(self, fill=False, **kwargs):
if self.random_start >= 2 and not fill:
super(FrameStackingEnv, self).reset(**kwargs)
for i in range(self.random_start - 2):
self.step(0)
first_frame, _, _, _ = super(FrameStackingEnv, self).step(0)
second_frame, _, _, _ = super(FrameStackingEnv, self).step(0)
frame = self._preprocess_frame(first_frame, second_frame)
for i in range(self.n):
self.buffer.append(frame)
return self.transform(torch.stack(tuple(self.buffer), dim=0))
elif 0 < self.random_start < 2 and not fill:
super(FrameStackingEnv, self).reset(**kwargs)
first_frame, _, _, _ = super(FrameStackingEnv, self).step(0)
second_frame, _, _, _ = super(FrameStackingEnv, self).step(0)
frame = self._preprocess_frame(first_frame, second_frame)
for i in range(self.n):
self.buffer.append(frame)
return self.transform(torch.stack(tuple(self.buffer), dim=0))
else:
first_frame = super(FrameStackingEnv, self).reset(**kwargs)
second_frame = super(FrameStackingEnv, self).reset(**kwargs)
frame = self._preprocess_frame(first_frame, second_frame)
for i in range(self.n):
self.buffer.append(frame)
return self.transform(torch.stack(tuple(self.buffer), dim=0))
"""
Take the action once and get the return value for the step in the environment
Repeat the action frame_skip - 2 times. In the frame_skip - 1 action, save the frame
in order to preprocess the current and the last frame of the `render` method
"""
def step(self, action, frame_skip=4):
if frame_skip < 2:
obs, reward, _done, info = super(FrameStackingEnv, self).step(action)
return obs, reward, _done, info
reward_sum = 0
done = False
# info = None
for i in range(0, frame_skip - 2):
obs, reward, _done, info = super(FrameStackingEnv, self).step(action)
reward_sum += reward
done = done or _done
# second-to-last frame
obs, reward, _done, info = super(FrameStackingEnv, self).step(action)
reward_sum += reward
self.last_unprocessed_frame = obs
done = done or _done
# last frame
obs, reward, _done, info = super(FrameStackingEnv, self).step(action)
reward_sum += reward
done = done or _done
frame = self._preprocess_frame(self.last_unprocessed_frame, obs)
# 0,1,2 -> 1,2,3
# self.buffer[:, :, 1:self.n] = self.buffer[0:self.n-1]
# self.buffer[:, :, 0] = frame
self.buffer.append(frame)
return self.transform(torch.stack(tuple(self.buffer), dim=0)), reward_sum, done, info
def render(self, mode='human', *kwargs):
# if save_temp_frame and mode == 'rgb_array':
# self.last_unprocessed_frame = super(FrameStackingEnv, self).render('rgb_array')
if mode == 'rgb_array':
return self.buffer.copy(), super(FrameStackingEnv, self).render('rgb_array')
return super(FrameStackingEnv, self).render(mode)
def snapshot(self):
state = self.env.clone_state() # make snapshot for atari. load with .restoreState()
return state, self.buffer.copy()
def restore_state_and_buffer(self, state, buffer):
self.env.restore_state(state)
self.buffer = buffer.copy()
return self.transform(torch.stack(tuple(self.buffer), dim=0))
After talking to a colleague and him not seeing anything wrong with the general algorithm, I thought, my wrappers might be the problem here, so I tried using the official atari_wrappers from the baselines repository. The resulting algorithm you can find here. I have only added one line to the atari wrappers to adjust for PyTorch:
self._out = np.transpose(self._out, (2, 0, 1)) in the LazyFrames class.
This implementation does not learn anything at all and also runs magnitudes slower. Looking at the state action values during the test runs, I can see that values for all states are the same, i.e. do not change during the run, but do change between runs:
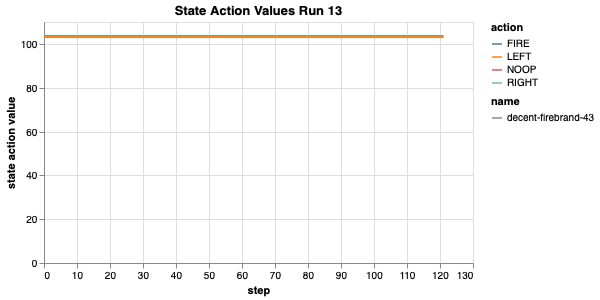
It looks like it is learning something but also nothing.
I’ve been at this for a few weeks now and I feel like I’m going crazy, so I’d really appreciate if someone can tell me what I did wrong!
Thank you very much!