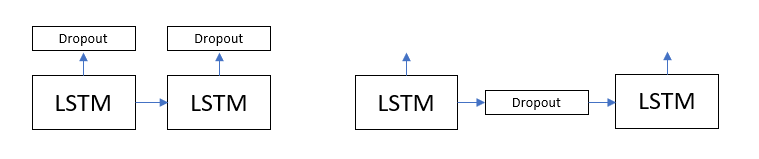
Hi, I was experimenting with LSTMs and noted that the dropout was applied at the output of the LSTMs like in the figure in the left below . I was wondering if it is possible to apply the dropout at the state transitions instead like on the right.
Hello, does no one working at pytorch have an answer for this ?
you can do that by manually unrolling LSTM. The output of LSTM will be output, (hn,cn). You can apply dropout to (hn,cn) via a dropout layer.
Ok I use this
for i in range(np.shape(x)[1]):
output, self.hidden = self.lstm(x[:,i,None,:], self.hidden)
But now I get the error
RuntimeError: Trying to backward through the graph a second time, but the buffers have already been freed. Specify retain_graph=True when calling backward the first time.$
Last time I use
self.lstm = nn.LSTM(feature_dim, hidden_size=hidden_dim, num_layers=num_layers, batch_first=True, dropout = 0.7)
self.h0 = Variable(torch.randn(num_layers, batch_size, hidden_dim))
self.c0 = Variable(torch.randn(num_layers, batch_size, hidden_dim))
# fc layers
self.fc1 = nn.Linear(hidden_dim, 2)
def forward(self, x, mode=False):
output, hn = self.lstm(x, (self.h0,self.c0))
output = self.fc1(output[:,-1,:])
and everything work. Why ?
where can i find an example that trains an unrolled lstm ?
Take a look at this please:
I am not sure why you are having that problem, but please check the type of your input to lstm.
Thank you I got it to work ! But it seems to run a lot slower than before. I guess its because I am extracting every row (timestep) of the array.
Its actually not working. Gonna post another thread for it.
can you explain a bit what you you mean by not working?
Thank you for your continued help sir  I have 2 versions of my code. I only paste the ones that I changed.
I have 2 versions of my code. I only paste the ones that I changed.
I have verified that this version is working
class Net(nn.Module):
def __init__(self, feature_dim, hidden_dim, batch_size):
super(Net, self).__init__()
num_layers=1
# single layer lstm
self.lstm = nn.LSTM(feature_dim, hidden_size=hidden_dim, num_layers=num_layers, batch_first=True, dropout = 0.7)
self.hn = Variable(torch.randn(num_layers, batch_size, hidden_dim))
self.cn = Variable(torch.randn(num_layers, batch_size, hidden_dim))
# fc layers
self.fc1 = nn.Linear(hidden_dim, 2)
def forward(self, x, mode=False):
for xt in torch.t(x):
output, (hn, cn) = self.lstm(xt[:,None,:], (self.hn,self.cn))
output = self.fc1(output[:,0,:])
return output
I realized that I made a mistake and that I should be passing the output to self.hn and self.cn. I made the changes as follows
class Net(nn.Module):
def __init__(self, feature_dim, hidden_dim, batch_size):
super(Net, self).__init__()
num_layers=1
# single layer lstm
self.lstm = nn.LSTM(feature_dim, hidden_size=hidden_dim, num_layers=num_layers, batch_first=True)
self.hn = Variable(torch.randn(num_layers, batch_size, hidden_dim))
self.cn = Variable(torch.randn(num_layers, batch_size, hidden_dim))
# fc layers
self.fc1 = nn.Linear(hidden_dim, 2)
def forward(self, x, mode=False):
# step through the sequence one timestep at a time
for xt in torch.t(x):
output, (self.hn, self.cn) = self.lstm(xt[:,None,:], (self.hn,self.cn))
output = self.fc1(output[:,0,:])
return output
And it now returns me
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
<ipython-input-5-4ad996d02c13> in <module>()
9 # train model
10 #tr_loss, te_loss = bci.train_model(model, tr_input, tr_target, 4, te_input, te_target, 4, 500)
---> 11 tr_err, te_err, tr_loss, te_loss = bci.train_model2(model, tr_input, tr_target, tr_target_onehot, 4, te_input, te_target, te_target_onehot, 4, 500)
12
13 # compute train and test errors
~\Desktop\Kong\project1\dlc_bci.py in train_model(model, train_input, train_target, tr_target_onehot, train_mini_batch_size, test_input, test_target, te_target_onehot, test_mini_batch_size, epoch)
165 # update the weights by subtracting the negative of the gradient
166 model.zero_grad()
--> 167 loss.backward()
168 optimizer.step()
169
~\Anaconda3\envs\dl\lib\site-packages\torch\autograd\variable.py in backward(self, gradient, retain_graph, create_graph, retain_variables)
165 Variable.
166 """
--> 167 torch.autograd.backward(self, gradient, retain_graph, create_graph, retain_variables)
168
169 def register_hook(self, hook):
~\Anaconda3\envs\dl\lib\site-packages\torch\autograd\__init__.py in backward(variables, grad_variables, retain_graph, create_graph, retain_variables)
97
98 Variable._execution_engine.run_backward(
---> 99 variables, grad_variables, retain_graph)
100
101
RuntimeError: Trying to backward through the graph a second time, but the buffers have already been freed. Specify retain_graph=True when calling backward the first time.
maybe the this discussion might help:
One thing I noticed is that h,c is initialized only once in your code when the class is instantiated. However, every time you start feeding a new sequence, you have to re-initialize h,c. Not sure if this is causing the issue though. You can add an init_hidden method to your class and use that to initialize hidden states every time you feed a new sequence.
Sorry but what did you mean by re-iintializing h and c ? Won’t I lose the updates done to h and c during backprop ?
h and c are not learned parameters. Check this example please:
http://pytorch.org/tutorials/beginner/nlp/sequence_models_tutorial.html#example-an-lstm-for-part-of-speech-tagging
Argh I totally forgot about that ! I have modified my code accordingly and it now works. Thank you very much for your continued assistance
class Net(nn.Module):
def __init__(self, feature_dim, hidden_dim, batch_size):
super(Net, self).__init__()
# lstm architecture
self.hidden_size=hidden_dim
self.input_size=feature_dim
self.batch_size=batch_size
self.num_layers=1
# lstm
self.lstm = nn.LSTM(feature_dim, hidden_size=self.hidden_size, num_layers=self.num_layers, batch_first=True)
# fc layers
self.fc1 = nn.Linear(hidden_dim, 2)
def forward(self, x, mode=False):
# initialize hidden and cell
hn = Variable(torch.randn(self.num_layers, self.batch_size, self.hidden_size))
cn = Variable(torch.randn(self.num_layers, self.batch_size, self.hidden_size))
# step through the sequence one timestep at a time
for xt in torch.t(x):
output, (hn,cn) = self.lstm(xt[:,None,:], (hn,cn))
output = self.fc1(output[:,0,:])
return output