Hi all,
I have been working on a CNN classification model for MRI scans that has a very small dataset and has been experiencing severe overfitting. Accordingly, I have been using dropout and data augmentation.
At the moment my model overfits with dropout = 0.8 but does not with dropout = 0.9. However, with such high dropout, the training accuracy appears mostly random (see the following plots)
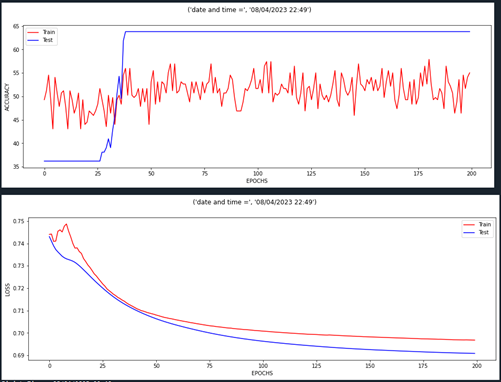
My question is, is it okay to disregard the bad training accuracy because everything else is fine (aka is it just a visual result of the dropout but the model is still performing well under the hood)? If not how should I rectify the model?