So, What i am basically trying to do can be summarized below.
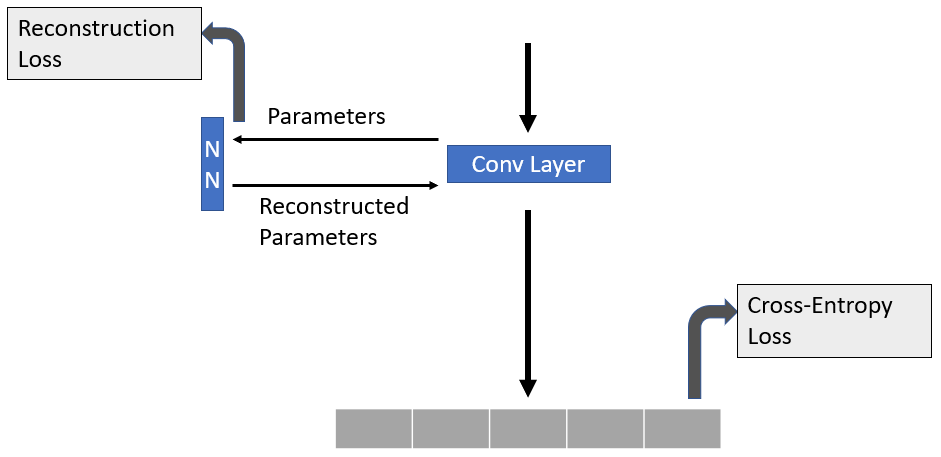
I want to reconstruct the parameter values of the weight of a convolutional layer and want to optimize the network on both this reconstruction loss and categorial cross-entropy loss. It works fine only while optimizing on cross-entropy loss but fails when I add the reconstruction loss. Basically the gradient is not passing through the NN(Neural Net) to update it’s parameter. I want it’s weight to get updated.
The network that I build was like below,
class MODEL(nn.Module):
def __init__(self):
super(MODEL, self).__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=64, kernel_size=(3,3), padding=1)
self.max_pool1 = nn.MaxPool2d(kernel_size=(3,3))
self.reBuilder = nn.Conv2d(in_channels=3, out_channels=3, kernel_size=(5,5), padding=2)
self.lossfn = torch.nn.L1Loss(reduction="mean")
self.conv2 = nn.Conv2d(in_channels=64, out_channels=256, kernel_size=(3,3), padding=1)
self.max_pool2 = nn.MaxPool2d(kernel_size=(3,3))
self.conv3 = nn.Conv2d(in_channels=256, out_channels=512, kernel_size=(3,3), padding=1)
self.max_pool3 = nn.MaxPool2d(kernel_size=(3,3))
self.dense = nn.Linear(in_features=512, out_features=10)
def forward(self, x):
ckpt = self.state_dict()
weight = ckpt["conv1.weight"].detach().clone().permute((3,2,1,0)) #output_shape (3,3,3,64)
weightNew = self.reBuilder(weight)
loss = self.lossfn(weightNew, weight)
weightNew = weightNew.permute((3, 2, 1, 0))
weightFinal = weightNew.detach().clone()
ckpt["conv1.weight"] = weightFinal
self.load_state_dict(ckpt)
x = self.conv1(x)
x = self.max_pool1(x)
x = self.conv2(x)
x = self.max_pool2(x)
x = self.conv3(x)
x = self.max_pool3(x)
x = torch.flatten(x, start_dim=1)
x = self.dense(x)
return x, loss
The forward and backward pass code is like,
model = MODEL()
criterion = nn.BCEWithLogitsLoss().to("cuda")
outputs, recoLoss = model(images)
ceLoss = criterion(outputs, targets)
loss = ceLoss + recoLoss
loss.backward()
optimizer.step()
If loss contains only ceLoss it works. But when I add recoLoss term it gives the following error.
"RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation: [torch.cuda.FloatTensor [3, 3, 5, 5]] is at version 2; expected version 1 instead. Hint: enable anomaly detection to find the operation that failed to compute its gradient, with torch.autograd.set_detect_anomaly(True)."
basically it is saying that, the parameters of the NN(in picture) or self.reBuilder in code have been modified already.
Can anyone help me in this regard?