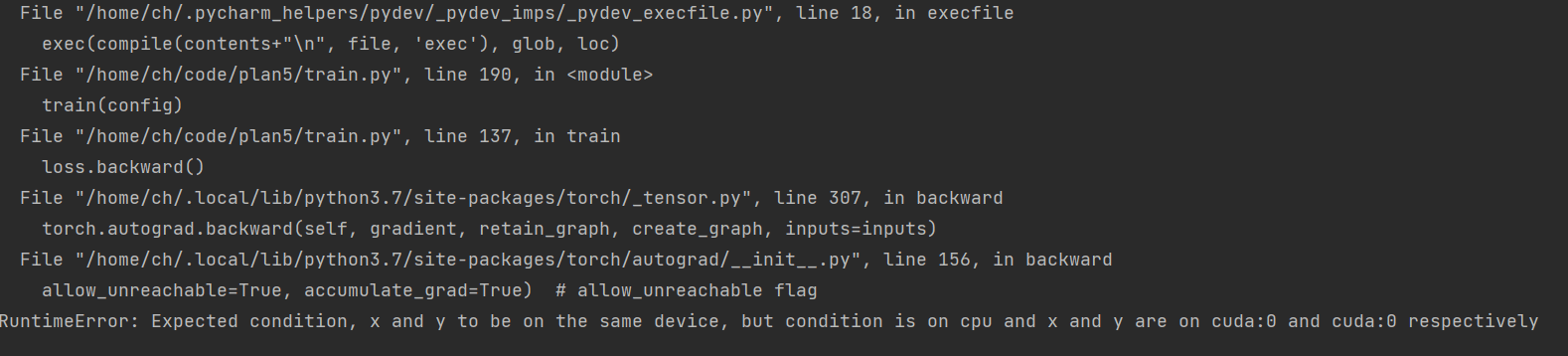
Thank you for your reply. The thin version of the code and error reporting are shown below:
def run(x, n, sigma):
r1 = torch.pow(x, n) / (torch.pow(x, n) + torch.pow(sigma, n) + 1e-6)
return r1
#######################
U_Net
#######################
class DoubleConv(nn.Module):
“”“(convolution => [BN] => ReLU) * 2"”"
def __init__(self, in_channels, out_channels, mid_channels=None):
super().__init__()
if not mid_channels:
mid_channels = out_channels
self.double_conv = nn.Sequential(
nn.Conv2d(in_channels, mid_channels, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(mid_channels),
nn.ReLU(inplace=True),
nn.Conv2d(mid_channels, out_channels, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
def forward(self, x):
return self.double_conv(x)
class Down(nn.Module):
“”“Downscaling with maxpool then double conv”“”
def __init__(self, in_channels, out_channels):
super().__init__()
self.maxpool_conv = nn.Sequential(
nn.MaxPool2d(2),
DoubleConv(in_channels, out_channels)
)
def forward(self, x):
return self.maxpool_conv(x)
class Up(nn.Module):
“”“Upscaling then double conv”“”
def __init__(self, in_channels, out_channels, bilinear=True):
super().__init__()
# if bilinear, use the normal convolutions to reduce the number of channels
if bilinear:
self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
self.conv = DoubleConv(in_channels, out_channels, in_channels // 2)
else:
self.up = nn.ConvTranspose2d(in_channels, in_channels // 2, kernel_size=2, stride=2)
self.conv = DoubleConv(in_channels, out_channels)
def forward(self, x1, x2):
x1 = self.up(x1)
# input is CHW
diffY = x2.size()[2] - x1.size()[2]
diffX = x2.size()[3] - x1.size()[3]
x1 = F.pad(x1, [diffX // 2, diffX - diffX // 2,
diffY // 2, diffY - diffY // 2])
x = torch.cat([x2, x1], dim=1)
return self.conv(x)
class OutConv(nn.Module):
def init(self, in_channels, out_channels):
super(OutConv, self).init()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=1)
def forward(self, x):
return self.conv(x)
“”" Full assembly of the parts to form the complete network “”"
class UNet(nn.Module):
def init(self, n_channels=16, n_classes=1, bilinear=False):
super(UNet, self).init()
self.n_channels = n_channels
self.n_classes = n_classes
self.bilinear = bilinear
self.inc = DoubleConv(n_channels, 64)
self.down1 = Down(64, 128)
self.down2 = Down(128, 256)
factor = 2 if bilinear else 1
self.down3 = Down(256, 512 // factor)
# factor = 2 if bilinear else 1
# self.down4 = Down(512, 1024 // factor)
# self.up1 = Up(1024, 512 // factor, bilinear)
self.up2 = Up(512, 256 // factor, bilinear)
self.up3 = Up(256, 128 // factor, bilinear)
self.up4 = Up(128, 64, bilinear)
self.outc = OutConv(64, n_classes)
def forward(self, x):
x1 = self.inc(x)
x2 = self.down1(x1)
x3 = self.down2(x2)
x4 = self.down3(x3)
#x5 = self.down4(x4)
#x = self.up1(x5, x4)
x = self.up2(x4, x3)
x = self.up3(x, x2)
x = self.up4(x, x1)
logits = torch.sigmoid(self.outc(x))
return logits
class net1(nn.Module):
def init(self,en_net=UNet(n_channels=10)):
super(net1,self).init()
self.en = en_net
self.conv1 = nn.Sequential(nn.Conv2d(1,16, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(16),
nn.ReLU(inplace=True))
self.conv2=nn.Conv2d(16,1,1,1,bias=False)
def forward(self, x):
output = []
n = torch.ones(10)
sigma = torch.linspace(0.1, 1.0, 10)
input = self.conv1(x)
input = torch.sigmoid(self.conv2(input))
for i in range(len(n)):
output.append(run(input,n[i],sigma[i]))
x_fusion = output[0]
for i in range(9):
x_fusion = torch.cat([x_fusion, output[i + 1]], dim=1)
out = self.en(x_fusion)
return input, out, 0.3*input, n, sigma, output
class net2(nn.Module):
def init(self,en_net=UNet(n_channels=16)):
super(net2,self).init()
self.en = en_net
self.conv1 = nn.Sequential(nn.Conv2d(1, 16, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(16),
nn.ReLU(inplace=True))
self.conv2=nn.Conv2d(16,1,1,1,bias=False)
def forward(self, x):
output = []
sigma = x.mean() * torch.ones(16).cuda()
n = torch.linspace(0.5, 8, 16)
input = self.conv1(x)
input = torch.sigmoid(self.conv2(input))
for i in range(len(n)):
output.append(run(input,n[i],sigma[i]))
x_fusion = output[0]
for i in range(15):
x_fusion = torch.cat([x_fusion, output[i + 1]], dim=1)
out = self.en(x_fusion)
return input, out, 0.3*input, n, sigma, output
class net3(nn.Module):
def init(self,net1 = net1(), net2 = net2()):
super(net3,self).init()
self.n1 = net1
self.n2 = net2
def forward(self,x):
out1 = self.n1(x)
out2 = self.n2(out1[1])
return out2[0], out2[1], out1, out2
##################
train
##################
net = net3().cuda()
criterion = nn.MSELoss().cuda()
optimizer = torch.optim.Adam(net.parameters(), lr=config.lr, weight_decay=config.weight_decay)
net.train()
iteration = 0
start_time = time.time()
…
#Dataset loading was omitted
input = input.cuda()
target = target.cuda()
combine, output, _, _ = net(input)
loss = criterion(output,target) + 0.2*criterion(combine,target)
optimizer.zero_grad()
loss.backward()
I wonder what the “condition” means and how to fix this error issue.