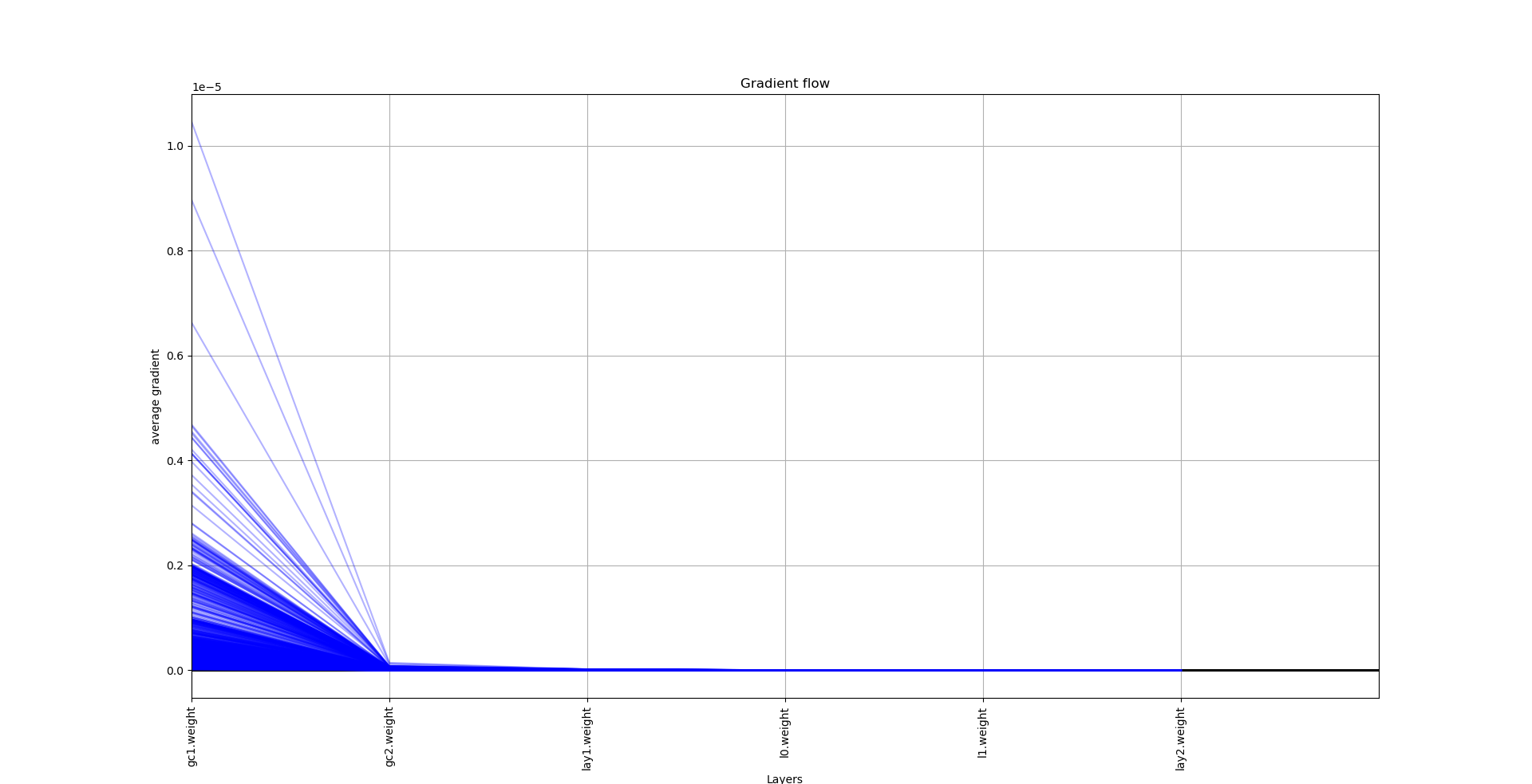
Hi,
I am using Pytorch-Geometric library to implement a Graph Neural Network for a regression problem. The model is defined as:
import torch
from torch.nn.parameter import Parameter
import torch.optim as optim
import torch.nn.functional as F
import torch.nn as nn
from torch_geometric.nn import GCNConv
class Model(nn.Module):
def __init__(self, nin=1, nhid1=128, nout=128, hid_l=64, out_l=1):
super(Model, self).__init__()
self.gc1 = GCNConv(in_channels= nin, out_channels= nhid1)
self.gc2 = GCNConv(in_channels= nhid1, out_channels= nout)
self.lay1 = nn.Linear(nout ,hid_l)
self.l0 = nn.Linear(hid_l,hid_l)
self.l1 = nn.Linear(hid_l,hid_l)
self.lay2 = nn.Linear(hid_l ,out_l)
self.active = nn.LeakyReLU(0.1)
with torch.no_grad():
self.gc1.weight = Parameter(nn.init.uniform_(torch.empty(nin,nhid1),a=0.0,b=1.0))
self.gc1.bias = Parameter(nn.init.uniform_(torch.empty(nhid1),a=0.0,b=1.0))
self.gc2.weight = Parameter(nn.init.uniform_(torch.empty(nhid1,nout),a=0.0,b=1.0))
self.gc2.bias = Parameter(nn.init.uniform_(torch.empty(nout),a=0.0,b=1.0))
self.lay1.weight = Parameter(nn.init.uniform_(torch.empty(hid_l, nout ),a=0.0,b=1.0))
self.l0.weight = Parameter(nn.init.uniform_(torch.empty(hid_l, hid_l),a=0.0,b=1.0))
self.l1.weight = Parameter(nn.init.uniform_(torch.empty(hid_l, hid_l),a=0.0,b=1.0))
self.lay2.weight = Parameter(nn.init.uniform_(torch.empty(out_l,hid_l),a=0.0,b=1.0))
def forward(self, data):
x, adj = data.x, data.edge_index
x = self.active(self.gc1(x, adj))
x = self.active(self.gc2(x, adj))
x = self.active(self.lay1(x))
x = self.active(self.l0(x))
x = self.active(self.l1(x))
x = self.active(self.lay2(x))
return x
where x is the feature matrix of dimension [n X 1] and adj is the edge index used in Pytorch Geometric. The gradient seems to have a very sharp descent even when training for just 40 epochs with batch gradient descent. I am training on scale-free graphs with around 1K nodes and ~3K edges. What can I do to get a better gradient values?