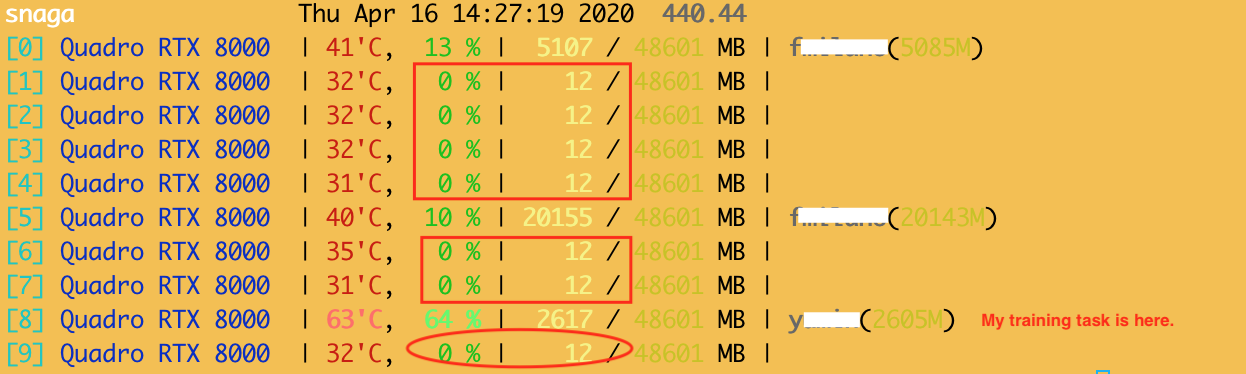
I use pytorch set cuda device to select the gpu I want to work on.
But the run will allocate processes on each GPU. For the GPU I selected, the data will be loaded there, uses as much memory as the training required. For those GPUs I didn’t select, each of them will occupy 12 MB, and have processes running, all processes have the same PID.
CUDA_VISIBLE_DEVICES=3 can’t solve my problem, because when I do this I will get invalid device ordinal error, meaning my training script is somehow doing some mysterious jobs as long as I start training, that it will “duplicate” the processes on each GPUs, and therefore all GPUs have to be visible.
Anyone can help this? It is quite embarrassing to let everyone on the server can see my jobs is everywhere. Thank you for your help.