Hi! I found that torch.softmax cause GPU memory leak.
My pytorch version is 1.8.1+cu111.
When I run the code below:
import torch
from torch import nn
from torch.nn import functional as F
from torch import cuda
def test(inp):
w = torch.rand([32, 1, 1, 1],device='cuda')
y = torch.softmax(F.conv2d(inp, w), 1)
y = F.conv_transpose2d(y, w)
return y
imgs = torch.zeros([128,1,512,512],device='cuda')
outp = test(imgs)
# del outp
cuda.empty_cache()
print(cuda.memory_summary())
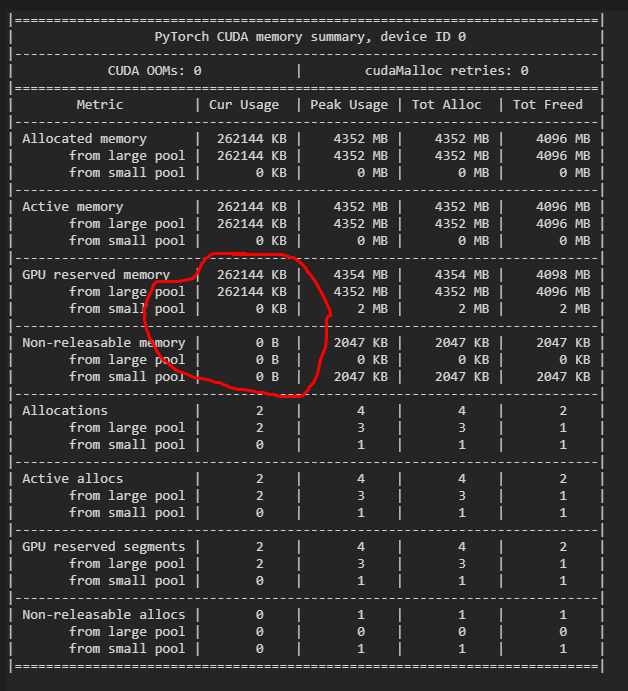
The output is:
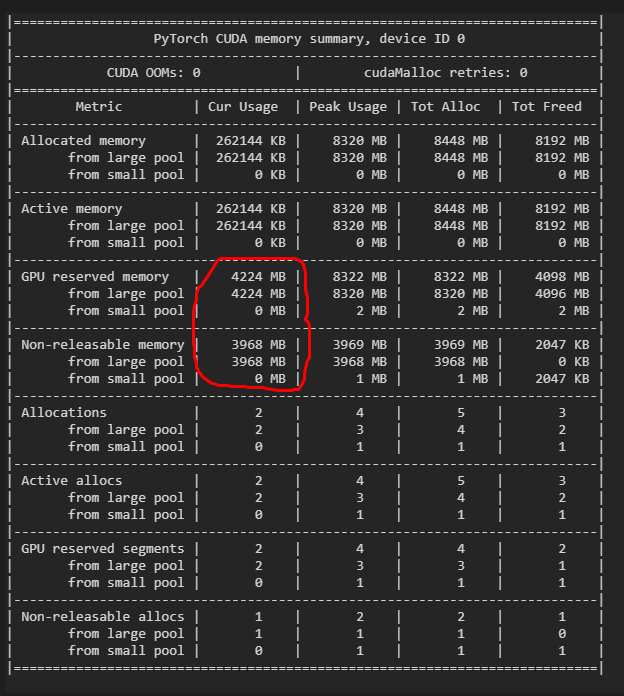
After the function outputs the result, the variables inside the function should be released, but it did not. In addition, if you delete the variable
outp, the redundant occupied memory will be released.For conparison, I wrote a softmax myself and it did not has the condition of memory leak. The code is below:
import torch
from torch import nn
from torch.nn import functional as F
from torch import cuda
def softmax(x,dim):
ex = torch.exp(x)
return ex/torch.sum(ex, dim,keepdim=True)
def test(inp):
w = torch.rand([32, 1, 1, 1],device='cuda')
y = softmax(F.conv2d(inp, w), 1)
y = F.conv_transpose2d(y, w)
return y
imgs = torch.zeros([128,1,512,512],device='cuda')
outp = test(imgs)
cuda.empty_cache()
print(cuda.memory_summary())
The output:
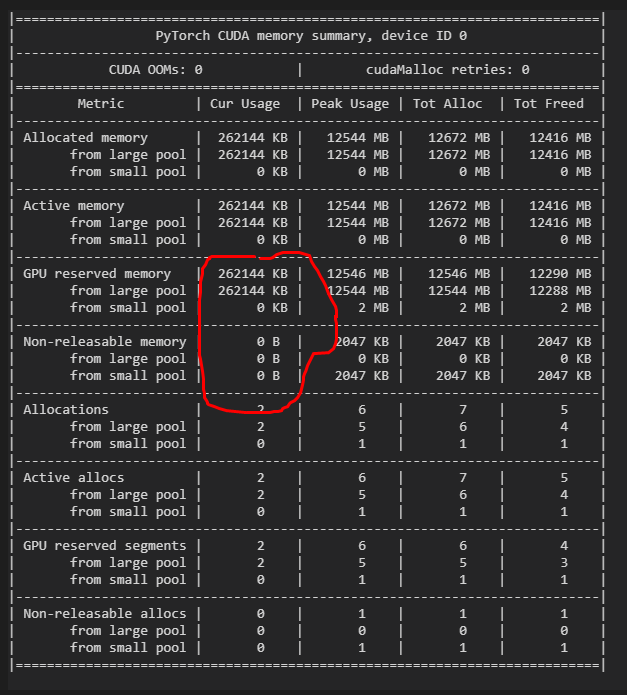
I don’t know what mechanism the non-releasable memory is. If it’s a bug, please fix it as soon as possible. Thanks
Another weird phenomenon! ![]()
![]()
![]()
![]()
I found that as long as I multiply a constant immediately after the first convolution, this kind of memory leak will occur. If you multiply the constant before feed into the ‘conv_transpose2d’ or not multiply the constant, the memory leak will disappear. The codes and results for the three cases are as follows:
import torch
from torch import nn
from torch.nn import functional as F
from torch import cuda
def test(inp):
w = torch.rand([32, 1, 1, 1],device='cuda')
a = F.conv2d(inp, w)*5
y = F.conv_transpose2d(a, w)
return y
imgs = torch.zeros([128,1,512,512],device='cuda')
outp = test(imgs)
cuda.empty_cache()
print(cuda.memory_summary())
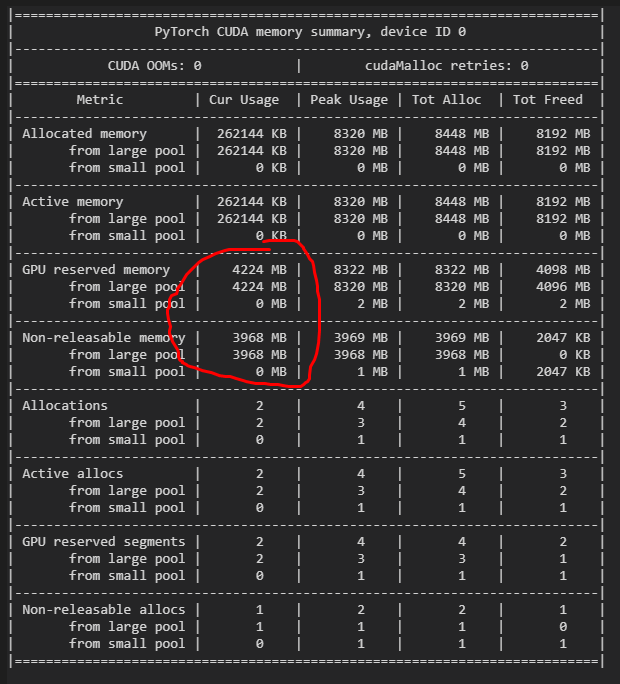
import torch
from torch import nn
from torch.nn import functional as F
from torch import cuda
def test(inp):
w = torch.rand([32, 1, 1, 1],device='cuda')
a = F.conv2d(inp, w)
y = F.conv_transpose2d(a*5, w)
return y
imgs = torch.zeros([128,1,512,512],device='cuda')
outp = test(imgs)
cuda.empty_cache()
print(cuda.memory_summary())
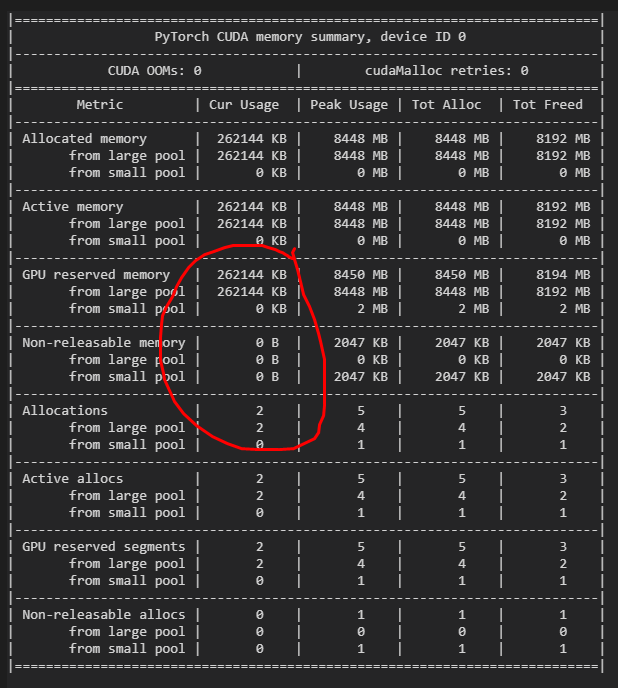
import torch
from torch import nn
from torch.nn import functional as F
from torch import cuda
def test(inp):
w = torch.rand([32, 1, 1, 1],device='cuda')
a = F.conv2d(inp, w)
y = F.conv_transpose2d(a, w)
return y
imgs = torch.zeros([128,1,512,512],device='cuda')
outp = test(imgs)
cuda.empty_cache()
print(cuda.memory_summary())
Please help me!!