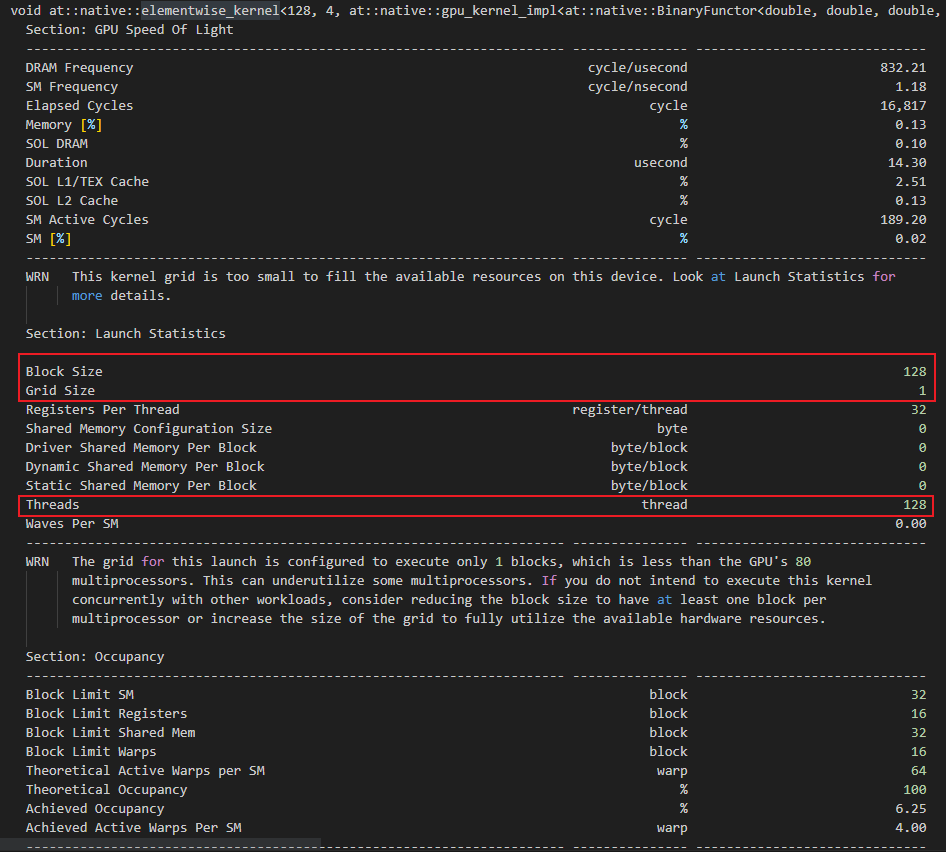
Hi, I am profiling my torch code using NVIDIA nsight-cli tool, and the experiment is on GPU V100. I found that elementwise_kernel is the most time-consuming. I found the actual reason is that the elementwise_kernel uses few cuda threads, for example, a two vector’s multiplication calls the elementwise_kernel, and the size of each vector is 500 in FP32, but the profiling result is that elementwise_kernel actually uses 128 threads, rather than 500 threads.
So my question is why does the elementwise_kernel use such few CUDA threads? Is it because the input size is too small?