Excuse me,
When I use the Embedding layer and randomly initialize it and update it during training, however, after one or two epochs, the weights in the Embedding layer change to nan, causing all subsequent model outputs to be nan, triggering “CUDA error: device-side assert triggered”, I want to know why the weights in the Embedding layer change to nan during training?
1 Like
Could you check the gradients in the embedding layer and see, if some large values are seen?
Also, are you sure this layer’s parameters are updated to NaN values? Could you run the code with torch.autograd.set_detect_anomaly(True) and post the stack trace here?
1 Like
Thanks,
i sure the enbedding layer’s weight are updated to NAN, because i debug the code and find this truth. But i use the clip=50/30/20/5/1, the problem still occur. And i plan to print the max value of the model’s weight between loss.backward() and model.step(). And i will also try your advice.
.
Oh! The stack trace as follow:
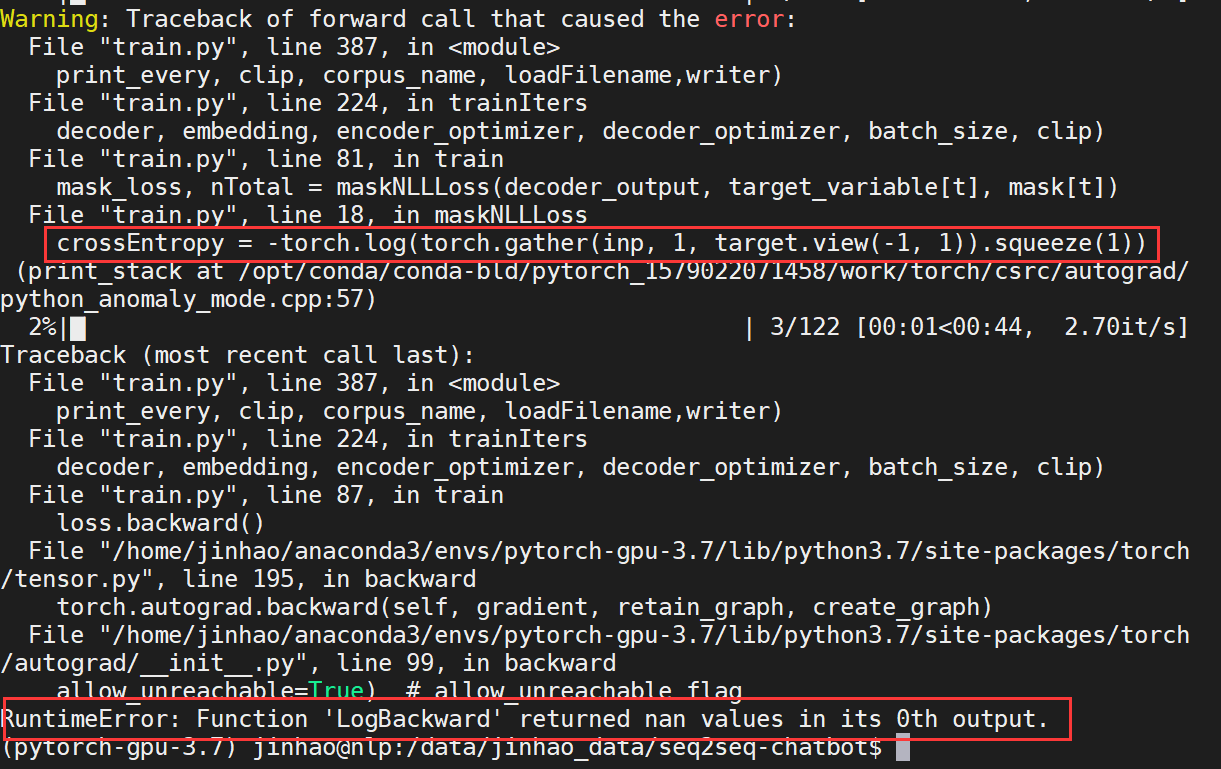
Here is my own mask_loss code:
def maskNLLLoss(inp, target, mask):
nTotal = mask.sum()
crossEntropy = -torch.log(torch.gather(inp, 1, target.view(-1, 1)).squeeze(1))
loss = crossEntropy.masked_select(mask).mean()
loss = loss.to(device)
return loss, nTotal.item()
The inp is the model output after F.softmax() compute and the target is the gold padding sequence and mask is the length mask. Are there some problem?
Here is the instance of the two variant:

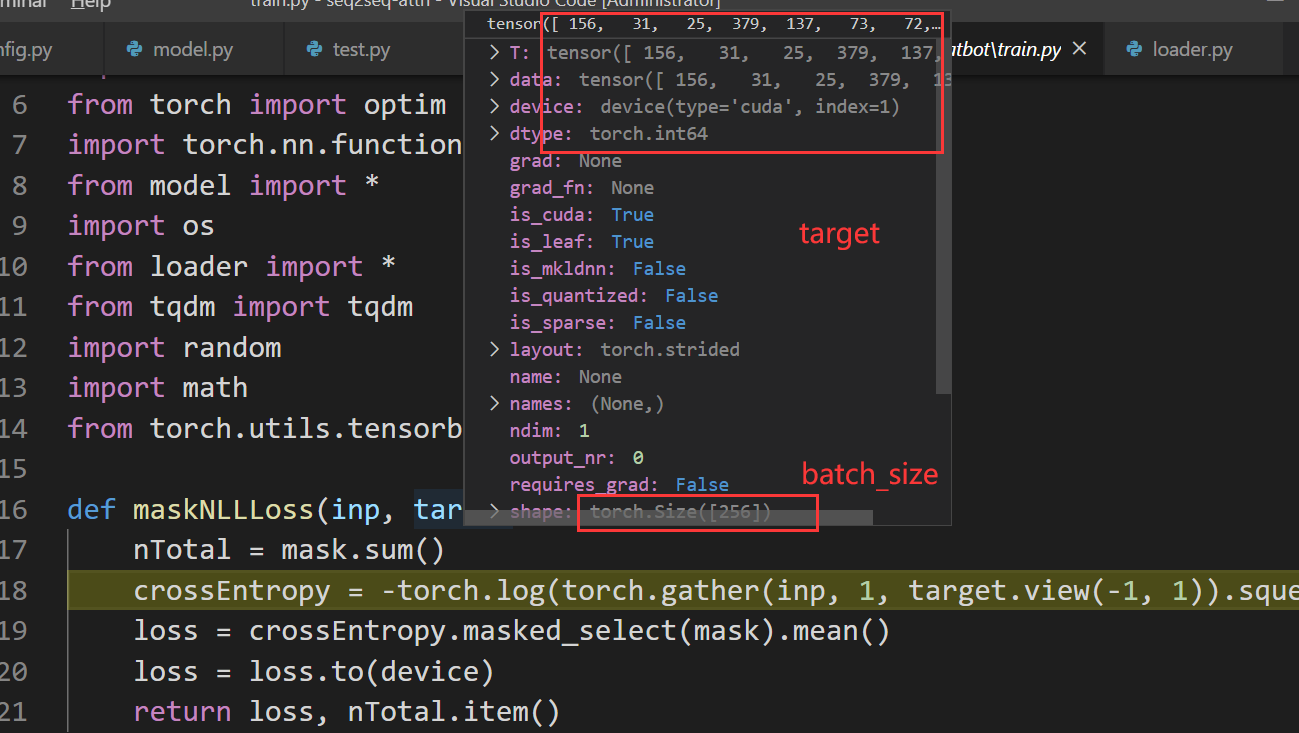
And i print the grad as follows:
--->encoder:
-->name: embedding.weight -->max_grad: tensor(4.5225e-05, device='cuda:1') -->min_grad: tensor(-3.6540e-05, device='cuda:1')
-->name: gru.weight_ih_l0 -->max_grad: tensor(0.0192, device='cuda:1') -->min_grad: tensor(-0.0180, device='cuda:1')
-->name: gru.weight_hh_l0 -->max_grad: tensor(0.0023, device='cuda:1') -->min_grad: tensor(-0.0025, device='cuda:1')
-->name: gru.bias_ih_l0 -->max_grad: tensor(0.0103, device='cuda:1') -->min_grad: tensor(-0.0094, device='cuda:1')
-->name: gru.bias_hh_l0 -->max_grad: tensor(0.0061, device='cuda:1') -->min_grad: tensor(-0.0049, device='cuda:1')
-->name: gru.weight_ih_l0_reverse -->max_grad: tensor(0.0164, device='cuda:1') -->min_grad: tensor(-0.0191, device='cuda:1')
-->name: gru.weight_hh_l0_reverse -->max_grad: tensor(0.0020, device='cuda:1') -->min_grad: tensor(-0.0021, device='cuda:1')
-->name: gru.bias_ih_l0_reverse -->max_grad: tensor(0.0077, device='cuda:1') -->min_grad: tensor(-0.0071, device='cuda:1')
-->name: gru.bias_hh_l0_reverse -->max_grad: tensor(0.0042, device='cuda:1') -->min_grad: tensor(-0.0040, device='cuda:1')
--->decoder:
-->name: embedding.weight -->max_grad: tensor(4.5225e-05, device='cuda:1') -->min_grad: tensor(-3.6540e-05, device='cuda:1')
-->name: gru.weight_ih_l0 -->max_grad: tensor(0.0208, device='cuda:1') -->min_grad: tensor(-0.0201, device='cuda:1')
-->name: gru.weight_hh_l0 -->max_grad: tensor(0.0040, device='cuda:1') -->min_grad: tensor(-0.0039, device='cuda:1')
-->name: gru.bias_ih_l0 -->max_grad: tensor(0.0061, device='cuda:1') -->min_grad: tensor(-0.0059, device='cuda:1')
-->name: gru.bias_hh_l0 -->max_grad: tensor(0.0039, device='cuda:1') -->min_grad: tensor(-0.0045, device='cuda:1')
-->name: concat.weight -->max_grad: tensor(0.0017, device='cuda:1') -->min_grad: tensor(-0.0017, device='cuda:1')
-->name: concat.bias -->max_grad: tensor(0.0012, device='cuda:1') -->min_grad: tensor(-0.0003, device='cuda:1')
-->name: out.weight -->max_grad: tensor(0.0440, device='cuda:1') -->min_grad: tensor(-0.0055, device='cuda:1')
-->name: out.bias -->max_grad: tensor(0.0170, device='cuda:1') -->min_grad: tensor(-0.0022, device='cuda:1')
The position of detect code as follows:
# Perform backpropatation
loss.backward()
# Clip gradients: gradients are modified in place
_ = nn.utils.clip_grad_norm_(encoder.parameters(), clip)
_ = nn.utils.clip_grad_norm_(decoder.parameters(), clip)
print("--->encoder:")
for name, params in encoder.named_parameters():
print("-->name:",name, "-->max_grad:", params.grad.max(), "-->min_grad:", params.grad.min())
print("--->decoder:")
for name, params in decoder.named_parameters():
print("-->name:",name, "-->max_grad:", params.grad.max(),"-->min_grad:", params.grad.min())
# Adjust model weights
encoder_optimizer.step()
decoder_optimizer.step()
Could you check, if you could possibly passing a zero or negative values to torch.log?
This would create a NaN/Inf output and thus yield to the mentioned issue.
However, the inp is the softmax output, it’s value in (0,1). So, it’s value not problem.
softmax can still return a zero, so it might be a problem:
x = torch.tensor([[-100000000000., 1., 1., 1.]])
print(torch.log(torch.softmax(x, 1)))
> tensor([[ -inf, -1.0986, -1.0986, -1.0986]])
Thanks,
so using the F.softmax() and F.cross_entropy() can solve this problem. what’s the difference between them.And this maskCrossEntropy is the chatbot tutorial of pytorch. And how to modify it?
F.cross_entropy expects logits, so you shouldn’t apply softmax in the input, as internally F.log_softmax will be used.
torch.log(torch.softmax()) should not be used, as it’s numerically less stable than torch.log_softmax.
For the dummy inputs of my previous post you’ll get:
print(torch.log_softmax(x, 1))
> tensor([[-1.0000e+11, -1.0986e+00, -1.0986e+00, -1.0986e+00]])
instead if the -inf output.
Could you link to the line of code, which is using torch.log(torch.softmax()), please?
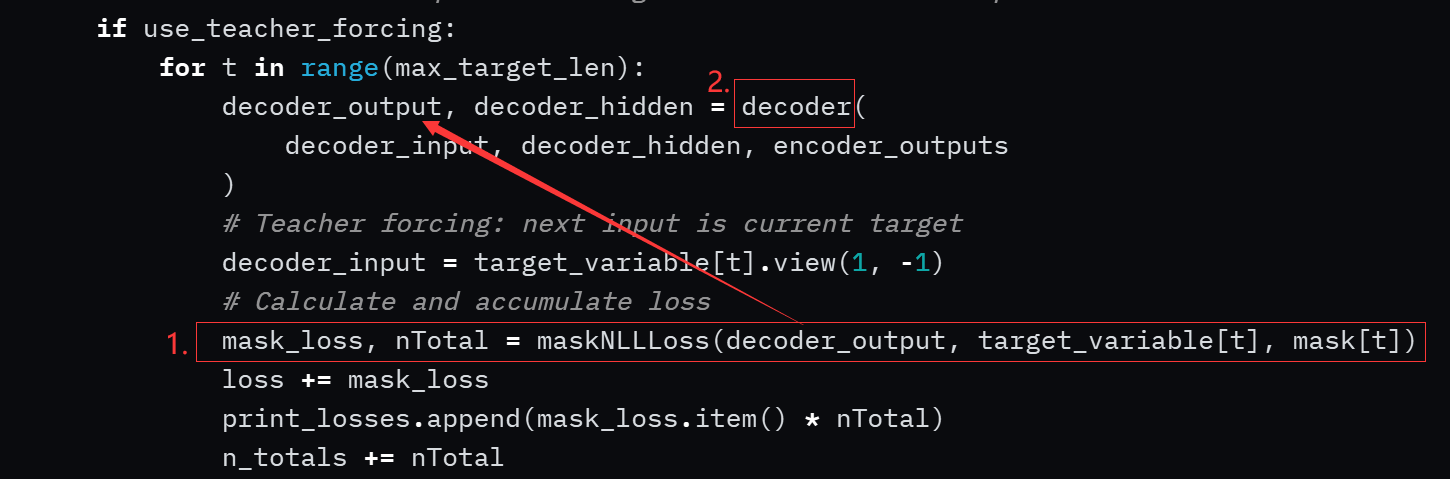
sorry, i can’t clearly show you the code detail, i just have screenshot and the code link, sorry again:
The code source as follows:
[tutorials/beginner_source/chatbot_tutorial.py at main · pytorch/tutorials · GitHub]
And the code detail as follows:

Thanks for the link. That’s generally not a good idea. Could you create an issue and describe the problem you ran into, please?
ok, i’ll try! Thanks for your help! This problem has trouble me 1 week. So, your help is very important ! Thanks again!
Sorry to hear that and thanks again for reporting this issue.
I think I have something similar? Could you please take a look?
class TokenPositionSegmentEmbedding(nn.Module):
def __init__(self,
vocabulary_size:int,
embedding_size:int,
maximum_length:int,
):
super(TokenPositionSegmentEmbedding, self).__init__()
# embedding for the tokens
self.token_embedding = nn.Embedding(vocabulary_size, embedding_size)
# embedding for corresponding position
self.position_embedding = nn.Embedding(maximum_length, embedding_size)
self.norm = nn.LayerNorm(embedding_size)
def forward(self, tokens):
sequence_length = tokens.size(1)
position = torch.arange(sequence_length, dtype=torch.long).to(tokens.device)
# (sequence_length,) -> (batch_size, sequence_length)
position = position.unsqueeze(0).expand_as(tokens)
embedding = (
self.token_embedding(tokens) + \
self.position_embedding(position)
)
# eventually embedding is nan
return self.norm(embedding)
1 Like
@SumNeuron me too ,how do solve it?