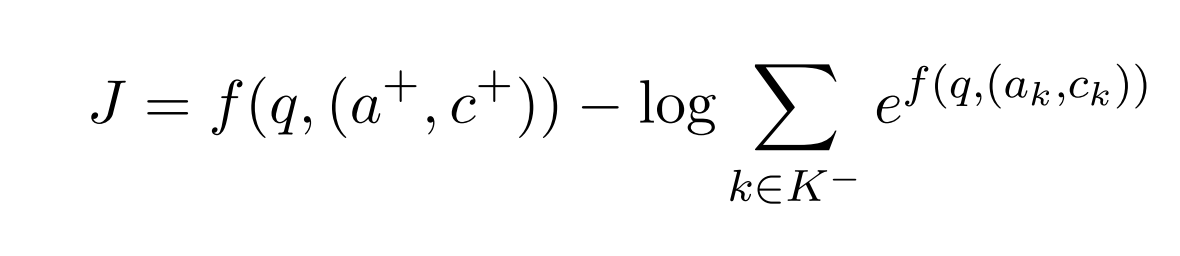Hi,
I try to build a neural network based on BertModel with the implementation from huggingface/transformers.
I basically take the bert-base-uncased model for contextual representation and another pretrained embedding layer for token-level representation. And do some operations in the network. I.E. Matrix multiplication between those two representations… But after training, I can’t see any updates for the embedding layer (i.e query_encoder in the network) by checking the same words’ embedding vector. Could you please help me with this, I think there is something wrong with the code.
import torch
import torch.nn as nn
import torch.nn.functional as F
from transformers import BertModel
class MyNet(nn.Module):
def __init__(self):
super(MyNet, self).__init__()
# embedding layer for question encoder
self.query_encoder = BertModel.from_pretrained("bert-base-uncased").embeddings.word_embeddings
self.query_encoder.weight.requires_grad = True
# bert encoder for answer, context embedding
self.context_encoder = BertModel.from_pretrained("bert-base-uncased")
# ReLU layer, bias append before relu.
self.bias = nn.Parameter(torch.FloatTensor([0.]), requires_grad=True)
self.relu = nn.ReLU()
def forward(self, query_tokens, context_tokens, batch_size, neg_pairs):
# get query embedding
# shape (batch_size, query_len, 768)
question_emb = self.query_encoder(query_tokens)
# get context embedding
# shape (batch_size, context_len, 768)
context_emb = self.context_encoder(**context_tokens).last_hidden_state
# batch multiply matrix
out = torch.bmm(question_emb, torch.transpose(context_emb, 1, 2))
op_dim = 2
if out.shape[0] == 2 * batch_size * neg_pairs:
out = out.view(batch_size, 2 * neg_pairs, out.shape[1], out.shape[2])
op_dim += 1
# max-pooling
out, _ = torch.max(out, dim=op_dim)
# add bias
out = out + self.bias
# relu
out = self.relu(out)
# log
out = torch.log(out + 1)
# summation
out = torch.sum(out, dim=op_dim-1)
return out
Could you check the .grad attribute of the weight tensor of the embedding layer(s), which are not updated?
Before the first backward call they should return a None object, while they should show valid gradient tensors afterwards.
If that’s not the case, the computation graph might be detached or the parameters might have been frozen.
Thanks for the reply : )
I checked the .grad attribute. It’s like what you said before the first backward call it returns None. And then it starts to return all 0s. Now I get why the embedding layer stays the same… But I still can’t figure out why… could you plz help me with this? Here is the loss_fn and train_epoch functions.
[Original formula for loss function which I aim to maximize]
def loss_fn(f_pos, f_negs, device):
"""
Loss function
"""
loss = None
for f_p, f_ns in zip(f_pos, f_negs):
if not loss:
loss = f_p - F.cross_entropy(f_ns.unsqueeze(0), torch.LongTensor([0]).to(device)) - f_ns[0]
else:
loss += f_p - F.cross_entropy(f_ns.unsqueeze(0), torch.LongTensor([0]).to(device)) - f_ns[0]
return -1 * loss
def train_epoch(myNet, my_dataLoader, device, batch_size,
loss_fn, optimizer, scheduler, writer):
"""
Train one epoch
"""
myNet.train()
losses = []
for batch_id, d in enumerate(tqdm(my_dataLoader, desc="Traning: ")):
print(myNet.query_encoder.weight.grad)
format_batch_tokens(d, batch_size)
optimizer.zero_grad()
f_pos_batch = myNet(d["pos"]["question_tokens"].to(device),
context_dict_to_device(d["pos"]["context_tokens"], device), batch_size, SIZE_NEGATIVE_PAIRS)
f_negs_batch = myNet(d["neg"]["question_tokens"].to(device),
context_dict_to_device(d["neg"]["context_tokens"], device), batch_size, SIZE_NEGATIVE_PAIRS)
loss = loss_fn(f_pos_batch, f_negs_batch, device)
writer.add_scalar("Loss/Batch", loss, batch_id)
losses.append(loss.item())
loss.backward()
nn.utils.clip_grad_norm(myNet.parameters(), max_norm=1.0)
optimizer.step()
scheduler.step()
optimizer.zero_grad()
return np.mean(losses)
Are you sure the gradients are zeros everywhere in the embedding weight parameter?
Note that only the selected weight “rows” will get a valid gradient, so depending on the way you’ve check it (e.g. by printing the .grad attribute only) it could look as if it’s all zeros.
Here is a small example to show the gradients:
emb = nn.Embedding(3, 4)
x = torch.tensor([[1]])
out = emb(x)
out.mean().backward()
print(emb.weight.grad)
> tensor([[0.0000, 0.0000, 0.0000, 0.0000],
[0.2500, 0.2500, 0.2500, 0.2500],
[0.0000, 0.0000, 0.0000, 0.0000]])
Yes, you are right. I re-check again with this snippet of code:
if spartaNet.query_encoder.weight.grad is not None:
print(torch.sum(spartaNet.query_encoder.weight.grad == 0).item() == 30522 * 768) # if all the rows' grad are 0s
else:
print("None")
And it always returns Ture. So the embedding layer’s grad is always 0. I am thinking that the gradients might be done to the indexes of tokens I’ve passed in, that’s why it is always 0s since they are constants?