import time
import numpy
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.autograd import Variable
from torch.nn.parameter import Parameter
class Toy(nn.Module):
def __init__(self):
super(Toy, self).__init__()
self.embed = nn.Embedding(100000, 256, sparse=False)
def forward(self, idx):
return F.sigmoid(self.embed(idx))
toy = Toy().cuda()
optimizer = optim.SGD(toy.parameters(), lr=0.001)
criterion = nn.CrossEntropyLoss().cuda()
x = Variable(
torch.from_numpy(numpy.random.randint(0, 100000, 256)).cuda(),
requires_grad=False
)
t = Variable(
torch.LongTensor(numpy.random.randint(0, 2, 256)).cuda(),
requires_grad=False
)
start_time = time.time()
for _ in xrange(2000):
y = toy(x)
cost = criterion(y, t)
cost.backward()
optimizer.step()
print time.time() - start_time
I tried this piece of code, the elapsed time is 18.3s (sparse=True) vs 3.84s (sparse=False) in a Tesla P100. I have Ubuntu 16 and CUDA8. Could someone please elaborate the some possible reasons?
Thank you in advance!
We recently fixed a performance issue with SGD on sparse gradients! If you checkout the master code, it should be vastly faster (and use much less memory!.
By default, momentum is zero, change in this PR is not reached. May I know when the binary release is built? Is this fix or relate fix is included?
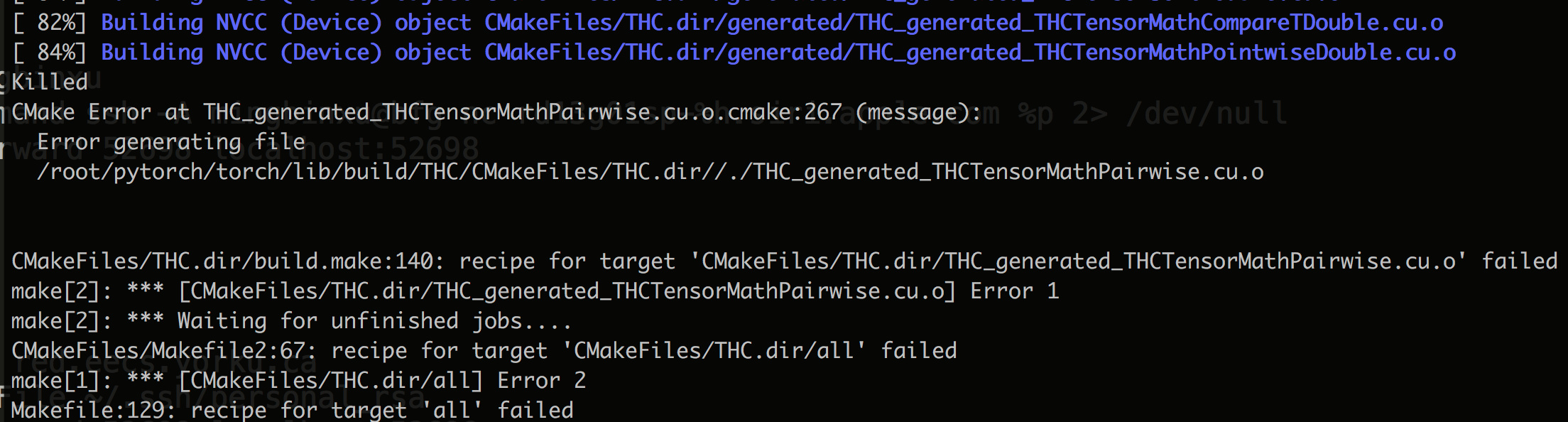
The source code doesn’t build on our server. I am guessing it’s due to out-of-date CUDA/driver/dependency. I don’t have root permission, which may take a lot time to verify who is the trouble maker. Could you please kindly update the binary release at your convenience?
Upon looking at the code, I realized that the problem is actually elsewhere. You should call optimizer.zero_grad() at beginning of each loop Otherwise, the gradient will just accumulate each loop (so its actually optimizing the wrong gradient values), and without calling coalesce(), sparse gradient can grow very large (each x index will have multiple values), causing the slow down.
After adding the zero_grad call, on current master, sparse version gives me 3.0683s and dense version gives me 7.5844s.
About updating binary. we will do so once we release a new version. Currently, if you need the new features/fixes, you can build from source by yourself. It’s very very simple to do so.
Thank you!
Could you please elaborate at which point I should call coalesce() on which variable?
I hit the following when building from source. May I have some advice? I have access to server with Ubuntu16.4, CUDA8.0, 6GB memory and a Tesla P100, but no root permission.
I’ve always been having a hard time reading Pytorch source code, sad.
Could you please tell me the underlying difference between Embedding being sparse or not?
My guess is that, with sparse=True, the forward/backward will only collect the rows from the whole huge Embedding matrix and compute grad for these ones; whereas with sparse=False, forward/backward will do the one-hot multiplication on the whole huge Embedding matrix, which involves much more computation than sparse=True version.