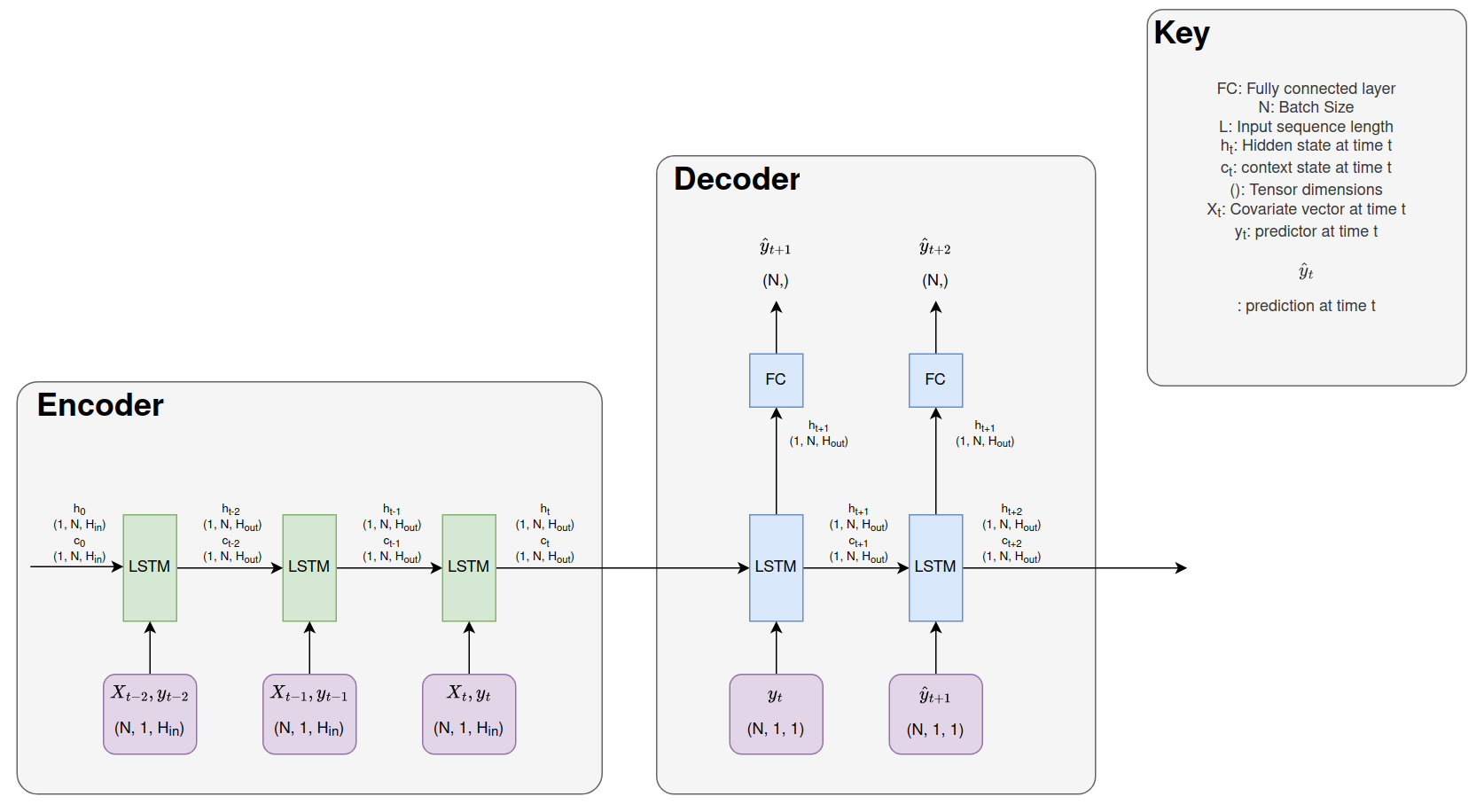
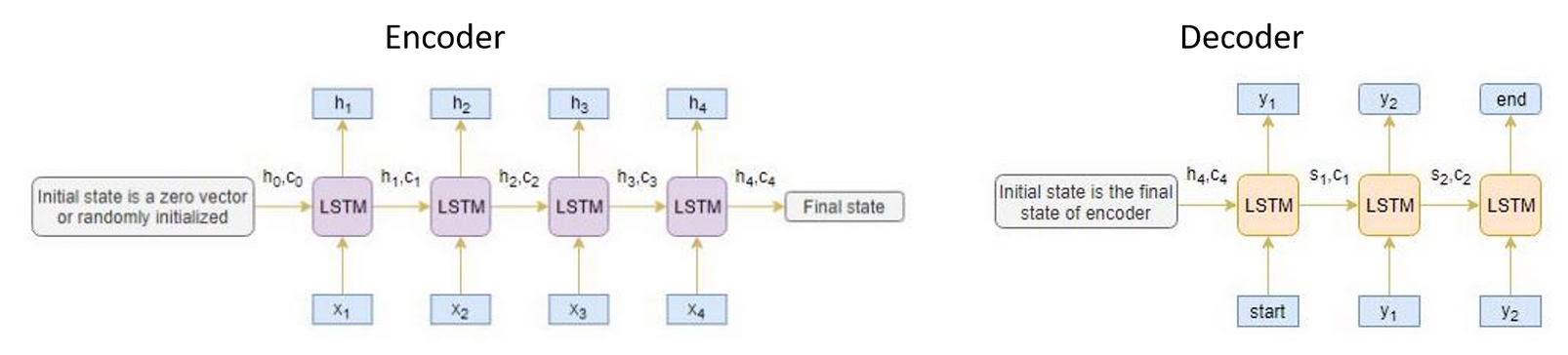
Sure here is the most minimal example I can give, I have broken the code into the classes for the encoder/decoder model and the minimal toy example to attempt to train the model on artificial data. Yes the hidden states are fed back into the encoder or decoder LSTM from where they came. The only example where this is not the case is where the final hidden state of the encoder is used as the initial hidden state of the decoder (which is how I understood an encoder/decoder network to work). Also I know in the code below that currently this will not work for a bidirectional LSTM even though it is possible to set this in the class when instantiating the class.
First the model classes:
import torch
import torch.nn as nn
from torch import optim
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
import numpy as np
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
class EncoderDecoderLSTM(nn.Module):
def __init__(self,
encoder_model,
decoder_model,
lr=0.001,
n_epochs=100,):
super(EncoderDecoderLSTM, self).__init__()
self.lr = lr
self.n_epochs = n_epochs
self.encoder_model = encoder_model
self.decoder_model = decoder_model
self.encoder_optimizer = optim.Adam(self.encoder_model.parameters(), lr=lr)
self.decoder_optimizer = optim.Adam(self.decoder_model.parameters(), lr=lr)
self.criterion = nn.MSELoss()
def train_epoch(self,
dataloader):
total_loss = 0
for data in dataloader:
input_tensor, target_tensor = data
self.encoder_optimizer.zero_grad()
self.decoder_optimizer.zero_grad()
# May need to initialise hidden?
encoder_hidden = self.encoder_model.init_hidden(batch_size=input_tensor.shape[0])
_, encoder_hidden = self.encoder_model.forward(input_tensor, encoder_hidden)
decoder_outputs, decoder_hidden, _ = self.decoder_model.forward(
decoder_input=input_tensor[:, -1, -1].unsqueeze(1).unsqueeze(1),
encoder_hidden=encoder_hidden)
loss = self.criterion(decoder_outputs, target_tensor)
loss.backward()
self.encoder_optimizer.step()
self.decoder_optimizer.step()
total_loss += loss.item()
return total_loss / len(dataloader)
def train(self,
dataloader):
for epoch in range(1, self.n_epochs + 1):
loss = self.train_epoch(dataloader)
class EncoderLSTM(nn.Module):
def __init__(self,
input_size,
hidden_dim,
batch_size,
n_layers,
bidirectional=False,
dropout_p=0.1):
super(EncoderLSTM, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_dim
self.batch_size = batch_size
self.bidirectional = bidirectional
self.dropout_p = dropout_p
self.n_layers = n_layers
self.lstm = nn.LSTM(input_size,
hidden_dim,
n_layers,
batch_first=True,
bidirectional=bidirectional,
dropout=dropout_p)
def forward(self, X, hidden):
print(f'Encoder Before:, input: {X.shape}, h: {hidden[0].shape}, c: {hidden[1].shape}')
output, hidden = self.lstm(X, hidden)
print(f'Encoder Final:, output: {output.shape}, h: {hidden[0].shape}, c: {hidden[1].shape}')
return output, hidden
def init_hidden(self, batch_size):
hidden = (torch.zeros(self.n_layers, batch_size, self.hidden_size),
torch.zeros(self.n_layers, batch_size, self.hidden_size))
return hidden
class DecoderLSTM(nn.Module):
def __init__(self, hidden_dim,
output_size,
batch_size,
n_layers,
forecasting_horizon,
bidirectional=False,
dropout_p=0,):
super(DecoderLSTM, self).__init__()
self.hidden_size = hidden_dim
self.output_size = output_size
self.batch_size = batch_size
self.bidirectional = bidirectional
self.dropout_p = dropout_p
self.forecasting_horizon = forecasting_horizon
self.lstm = nn.LSTM(hidden_dim,
hidden_dim,
n_layers,
batch_first=True,
bidirectional=bidirectional,
dropout=dropout_p)
self.out = nn.Linear(hidden_dim, output_size)
def forward(self,
decoder_input,
encoder_hidden):
decoder_hidden = encoder_hidden
decoder_outputs = []
for i in range(self.forecasting_horizon):
decoder_output, decoder_hidden = self.forward_step(decoder_input, decoder_hidden)
decoder_outputs.append(decoder_output)
decoder_input = decoder_hidden[0][-1, :, :].unsqueeze(0).permute(1, 0, 2)
decoder_outputs = torch.cat(decoder_outputs, dim=1)
return decoder_outputs, decoder_hidden, None # We return `None` for consistency in the training loop
def forward_step(self, X, hidden):
print(f'Decoder Before:, input: {X.shape}, h: {hidden[0].shape}, c: {hidden[1].shape}')
output, hidden = self.lstm(X, hidden)
print(f'Decoder After:, output: {output.shape}, h: {hidden[0].shape}, c: {hidden[1].shape}')
output = self.out(output)
print(f'Decoder Final:, output: {output.shape}, h: {hidden[0].shape}, c: {hidden[1].shape}')
return output, hidden
class SequenceDataset(Dataset):
def __init__(self, x, y):
self.x = torch.tensor(x, dtype=torch.float32)
self.y = torch.tensor(y, dtype=torch.float32)
self.len = x.shape[0]
def __getitem__(self, idx):
x = self.x[idx, :, :]
y = self.y[idx, :]
return x, y
def __len__(self):
return self.len
This is the minimal example to attempt to train the model using linear combinations of sine waves:
t = np.arange(0, 100).reshape((-1, 1))
x1 = np.sin(t)
x2 = 2*np.sin(0.8 * t)
x3 = np.sin(1.5 * t)
x4 = 0.1 * np.sin(0.1 * t)
x5 = np.sin(2 * t)
y = x1 + x2 + x3 + x4 + x5
data = np.hstack((x1, x2, x3, x4, x5, y))
# Chop the data into X and y data using a sliding window
forecast_horizon = 2 #No. of time steps into the future to predict
chunk_size = 3 #No. of previous time steps to use
max_counter = data.shape[0] - chunk_size - forecast_horizon
data_chunked_inputs = np.zeros((max_counter, chunk_size, data.shape[1]))
data_chunked_outputs = np.zeros((max_counter, forecast_horizon, 1))
counter = 0
start_time_input = 0
batch_size = 10
while counter < max_counter:
# Specify the start and end times for each chunk
end_time_input = start_time_input + chunk_size
start_time_output = end_time_input
end_time_output = start_time_output + forecast_horizon
# slice chunks
input_chunk = data[start_time_input:end_time_input, :]
output_chunk = data[start_time_output:end_time_output, -1].reshape((-1, 1))
data_chunked_inputs[counter, :, :] = input_chunk
data_chunked_outputs[counter, :, :] = output_chunk
start_time_input += 1
counter += 1
# Create the dataloader
dataset = SequenceDataset(x=data_chunked_inputs, y=data_chunked_outputs)
loader = DataLoader(dataset, shuffle=True, batch_size=batch_size)
# Set some arbitrary parameters
hidden_dim = 100
n_rnn_layers = 1
dropout = 0
learning_rate = 0.001
n_epochs = 100
# Initialise each of the models
model_encoder = EncoderLSTM(input_size=data.shape[1],
hidden_dim=hidden_dim,
batch_size=batch_size,
n_layers=n_rnn_layers,
bidirectional=False,
dropout_p=dropout)
model_decoder = DecoderLSTM(hidden_dim=hidden_dim,
output_size=1,
batch_size=batch_size,
n_layers=n_rnn_layers,
forecasting_horizon=forecast_horizon,
bidirectional=False,
dropout_p=0)
model_encoder_decoder = EncoderDecoderLSTM(encoder_model=model_encoder,
decoder_model=model_decoder,
lr=learning_rate)
# Attempt to train the model
model_encoder_decoder.train(dataloader=loader)
The error in the forward call of the lstm function of the decoder forward step method on the first iteration it is used:
RuntimeError: input.size(-1) must be equal to input_size. Expected 100, got 1