I am trying to implement below encoder-decoder model for videos (Paper: Unsupervised Learning of Video Representations using LSTMs ([1502.04681] Unsupervised Learning of Video Representations using LSTMs)),
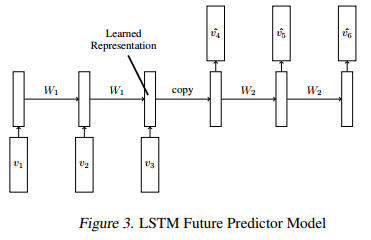
I have gone through Pytorch tutorial on Seq2Seq models for translations, and found in LSTM encoder-decoder models need SOS and EOS tokens.
I have some questions,
- In above network also do we need the two tokens, then how to include them.
- Are these tokens just a vector of zeroes and ones (which i can manually choose).
Thanks.