I am working on a full encoder-decoder transformer model to synthesize speech from EEG signals. Specifically, for a window of EEG activity of length x=100, I predict a window of length x =100 of mel spectrograms. The EEG and mel spectrograms are aligned in time, with total data set dimensions (43265, 107) for EEG and (43264, 80) for mel spectrograms.I divided the dataset into training and testing sets with an 80/20 split. This results in 6902 training sequences, each with dimensions (100, 107) for EEG and (100, 80) for mel spectrograms.My model architecture includes:
- Two prenets (one for the encoder and one for the decoder) to extract features from the EEG and mel spectrograms, projecting them into embeddings.
- A postnet to refine the predicted mel spectrograms.
The issue I’m facing is that while the training loss decreases, the model performs poorly during inference. The predictions on the validation set are very poor, and the model also underperforms on the training set during inference.During inference I predict the data the following way:
eeg_val = eeg_val.to(device)
mel_val = mel_val.to(device)
mel_input = torch.zeros([modelArgs.batch_size, 1, 80]).to(device)
pos_eeg = torch.arange(1, eeg_context_length + 1).repeat(modelArgs.batch_size, 1).to(device)
pbar = tqdm(range(config["TR"]["context_length"]), desc=f"Validating...", position=0, leave=False)
with torch.no_grad():
for _ in pbar: pos_mel = torch.arange(1, mel_input.size(1)+1).repeat(modelArgs.batch_size, 1).to(device)
mel_out, postnet_pred, attn, _, attn_dec = model.forward(eeg_val, mel_input, pos_eeg, pos_mel)
mel_input = torch.cat([mel_input, mel_out[:,-1:,:]], dim=1)
batch_loss = criterion(postnet_pred, mel_val)
where:
config["TR"]["context_length"]is the length of the window i.e.100pos_eegandpos_melare used to create masks for attentionmel_outis the output of the decoder,postnet_predis the output of the postnet
Training overview
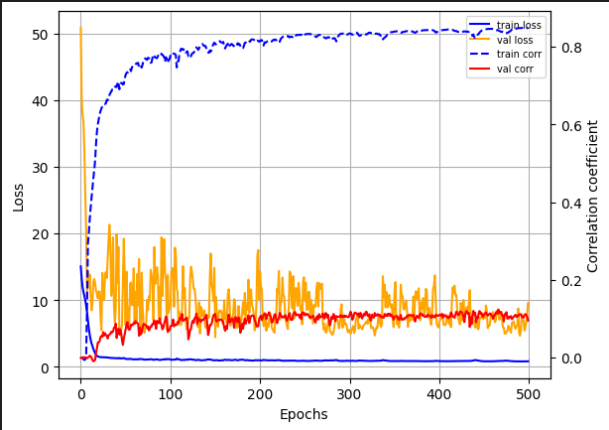
The loss is calculated with nn.L1Loss() on the output of the decoder and the output of the postnet: batch_loss = mel_loss + post_mel_loss
My model is based on the model from Neural Speech Synthesis with Transformer Network (2018) paper and I use the following implementationThe only difference between my setup and the text2Speech is that:
- I use EEG instead of text
- I don’t have a stop token as I predict for a fixed time window.
- I create positional embeddings using the following class instead of the
nn.Embeddingsmodule:
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout=0.1, max_len=200):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
self.alpha = nn.Parameter(t.ones(1))
pe = t.zeros(max_len, d_model)
position = t.arange(0, max_len, dtype=t.float).unsqueeze(1)
div_term = t.exp(t.arange(0, d_model, 2).float() * (-np.log(10000.0) / d_model))
pe[:, 0::2] = t.sin(position * div_term)
pe[:, 1::2] = t.cos(position * div_term)
self.register_buffer('pe', pe)
def forward(self, x):
pos = self.pe[:x.shape[1]]
pos = t.stack([pos]*x.shape[0], 0) # [bs x seq_len(x) x n_pos]
x = pos * self.alpha + x
return self.dropout(x)
I also use NoamOpt learning scheduler from this tutorial: https://nlp.seas.harvard.edu/2018/04/03/attention.html
Question: What surprises me the most is that despite a drastically increasing loss and very good correlation scores (between prediction and ground truth) during training, the network performs very poorly on the same training sequences during inference → What could be the reason for the model’s poor autoregressive performance?