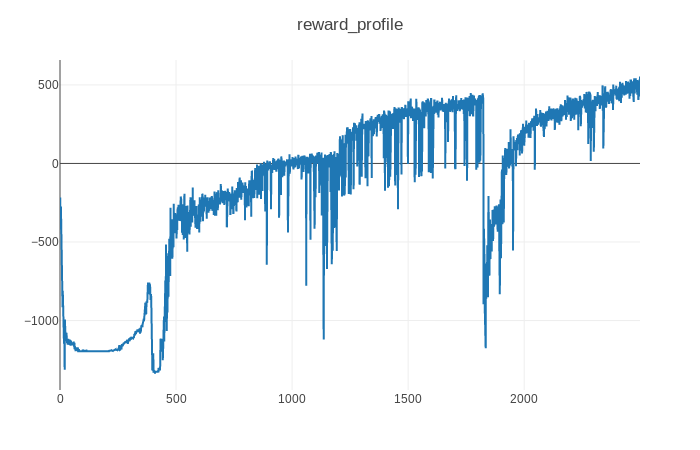
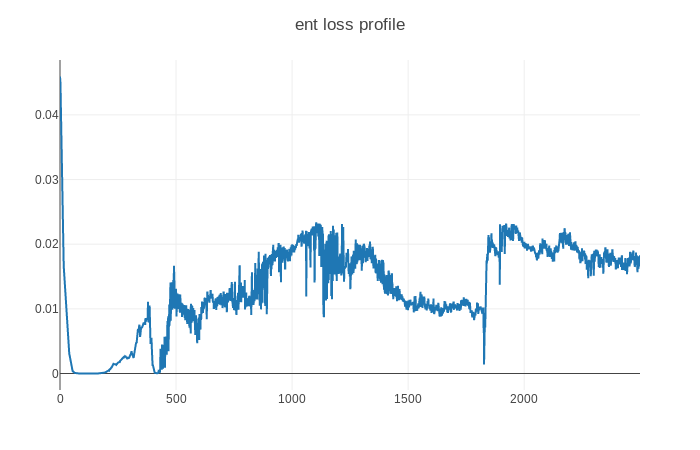
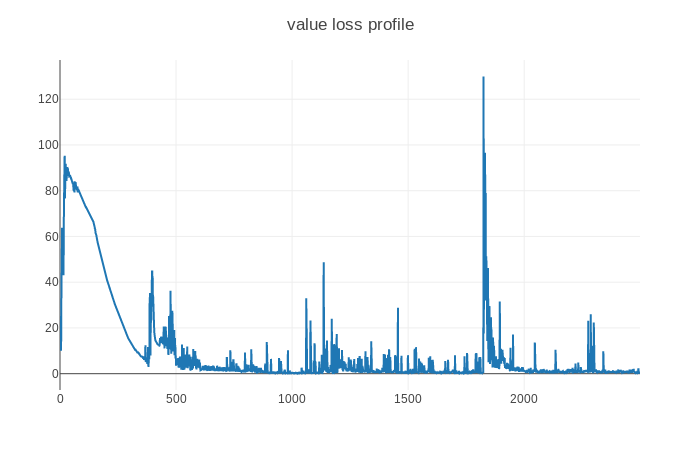
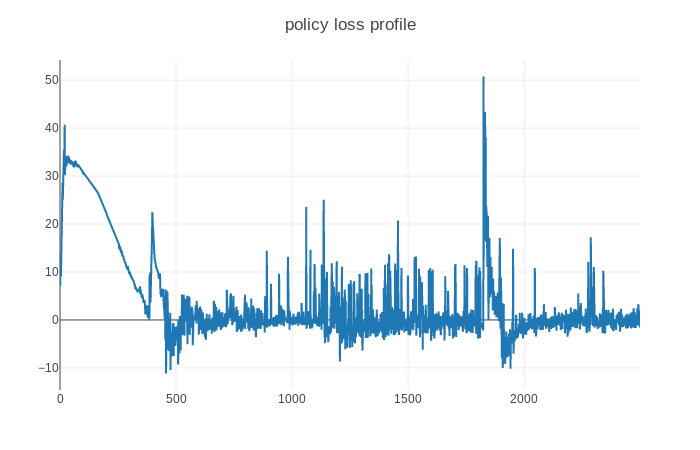
When I am training a drl agent with discrete action space using ppo-based algorithm, the training process is not stable and when training to 1800 episode around, the entropy loss deceases sharply and the agent got a really bad average reward. I have used nn.LayerNorm and state, reward is constrained to around (-1,1), Does anyone has some good suggestions?